









-
深度神经网络由于在特征表达与特征学习方面的优势,逐步取代传统算法。当前计算机视觉任务主要应用于可见光领域不同计算机视觉任务,包括图像分类[1]、语义分割[2]、目标检测[3]等。但是,可见光相机在夜视,雾霾等场景中无法获取可靠数据,从而限制了应用范围。InGaAs探测器响应波段为近红外波段,具有高灵敏度、高探测率、室温工作、低功耗、高均匀性等优异的技术特性。因此在夜视、航空航天等军事与民用领域广泛应用,弥补了可见光相机应用中的不足。
文中的目标是将深度学习应用于基于InGaAs探测器的智能探测设备,并结合人脸检测[4]应用,实现适用于低功耗探测设备的近红外人脸检测智能算法。人脸检测是重要的计算机视觉任务,是人脸识别[5],情绪分析[6],安防报警[7]等任务的基础。近红外人脸检测可以采用主动成像,确保了人脸成像质量,并且能够屏蔽部分打印人脸及电子显示设备中人脸的干扰。
文中对算法设计中两个主要技术问题进行研究: (1) InGaAs近红外人脸小样本学习。由于能够自主采集近红外人脸图像较少,同时网络中相关红外波段人脸数据不足,文中无法建立完整近红外人脸数据集用于训练与测试,需通过少量样本实现网络设计。(2) 模型轻量化设计。DNNs使用包含大量参数的复杂神经网络,以此获得丰富的图像特征,因而需要大量算力。对于低功耗探测器而言,硬件算力限制了算法设计,算法部署难度大。
目前,已有许多网络轻量化方法被提出,例如模型剪枝[8]、模型量化[9]等。网络量化将浮点数值表示的网络参数映射为固定的离散数值。以此将复杂的浮点计算替换为高效的固定比特计算或位运算,从而降低网络所需计算量。得益于Nvidia GPU等硬件支持,8 bit量化成为主流量化应用方案。但是,8 bit量化压缩率有限,为达到更高压缩率,二值量化成为重要研究方向。
另一方面,深度学习网络一般使用GPU以浮点数完成卷积所需的乘加运算,对于移动设备的算力与带宽提出了较高要求。而压缩后的二值网络可以部署于FPGA中,使用同或门(XNOR)与位计数代替浮点数乘法与累加操作,降低计算量的,实现最高128倍的理论性能提升。
二值量化神经网络研究起始于BNN[10],作者提出了二值网络梯度优化的基础方案,实现了DNNs中卷积层及激活层权重二值量化工作。但是,在ImageNet[11] top-1 识别任务中,BNN仅能实现42.2%识别准确度,相比于单精度网络72.4%的准确度存在较大差距。2020年,ReActNet[12]优化二值网络中的Sign函数及PReLU函数,最终识别准确度可达69.4%。将二值网络与1网络准确度差距缩小至3%。
深度学习需要大数据作为支撑,但为不同的任务单独建立数据集成本过高,包含大量重复工作。因此小样本学习成为重要的研究方向。目前,数据增强,元学习,迁移学习等方案被用于解决小样本问题。其中,迁移学习通过已有知识迁移新知识的方法,使新网络快速应用于新任务。
文中将二值量化、迁移学习用于网络设计,提出了名为ReactFace的超轻量红外人脸检测网络方案。它实现了以下目标:(1)基于Single Shot MultiBox Detector(SSD)的二值化人脸检测基础网络设计;(2)通过特征校准的Sign函数和对抗卷积层减少二值量化带来的准确率损失;(3)实现可见光人脸检测算法向近红外人脸检测算法迁移。最终网络能够部署于FPGA低功耗设备中,并且对于FDDB人脸测试集,ReActNet与单精度网络准确度仅相差5%,在采集的红外人脸测试集中达到71.18%平均检测准确率。
-
SSD网络[13]是单阶段、端到端的目标检测网络。SSD采用全卷积网络设计方式,解决了图像尺寸变化产生的影响。同时,由于单阶段网络避免重复计算特征,实现了较快网络计算速度。采用结合anchor先验框等算法,SSD实现了接近双阶段网络[14]的检测效果。
为了达到更高压缩率,文中采用MobileNet v1[15]作为SSD的特征提取卷积网络。MobileNet v1采用卷积分离方法,减少了卷积网络参数量的同时,保持着良好的特征提取能力,适合于各类移动设备应用。
-
2020年,ReActNet[12]探究了ReLU和Sign函数对二值卷积网络的影响,证明了ReLU函数对网络特征学习能力产生许多影响。并据此提出了ReActNet网络应用于ImageNet分类任务中。ReActNet网络为Sign和ReLU函数增加偏置,并命名新函数为RSign及RPReLU,如公式(1)与公式(2)。
$$ x_i^b = {\rm{RSign}}(x_i^r) = \left\{ {\begin{array}{*{20}{c}} {1,}&{x_i^r \gt {\alpha _i}} \\ { - 1,}&{x_i^r \leqslant {\alpha _i}} \end{array}} \right. $$ (1) 式中:
$x_i^r$ 为第i层Sign函数输入特征;${\alpha _i}$ 为学习变量,经过训练的网络能够通过${\alpha _i}$ 调整Sign函数阈值。经过阈值调整后的Sign函数将实现更精确的二值化效果。公式(2)为RPReLU函数计算公式,式中:
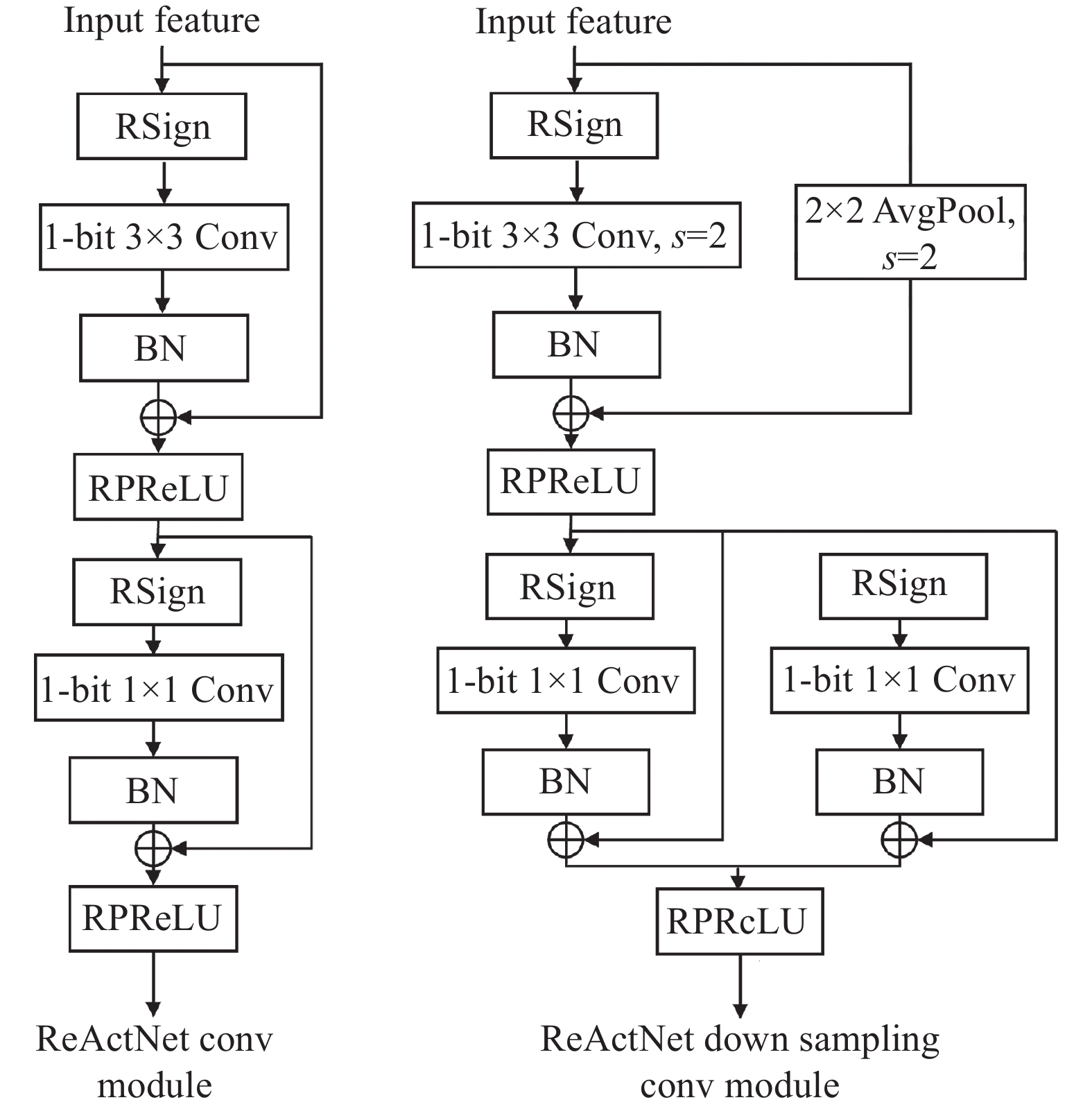
${x_i}$ 为输入特征;${\gamma _i}$ ${\beta _i}$ ${\zeta _i}$ 为学习变量。与PReLU相比,RPReLU增加了${\gamma _i}$ ${\zeta _i}$ 变量,使更多有效特征得以保留。$$ {\rm{RPReLU}}({x_i}) = \left\{ {\begin{array}{*{20}{c}} {{x_i} - {\gamma _i} + {\zeta _i},}&{{\rm{if}}\;{x_i} \gt {\gamma _i}} \\ {{\beta _i}({x_i} - {\gamma _i}) + {\zeta _i},}&{{\rm{if}}\;{x_i} \leqslant {\gamma _i}} \end{array}} \right. $$ (2) ReActNet同时修改了MobileNet v1中的可分离卷积模块,如图1所示。与原卷积分离模块不同,ReActNet模块增加了RSign与RPeLU函数,并通过shortcut方式加强了网络的训练效果。与XNOR-Net相比,ReActNet对于ImageNet top1识别准确度提升了18.2%。

图 1 ReActNet模块框图
Figure 1. Module of ReActNet
目前,ReActNet网络仅在图像分类任务中取得了良好的效果。文中将其应用于目标检测任务中发现,与识别任务不同,使用ReActNet为特征提取网络的模型检测准确度出现了大幅下降。
图2展示了卷积网络特征传递情况。(a)为输入图片; (b)为ReActNet模块输入特征图,即图1中F1特征;(c)为经过RSign函数量化后的特征图片,即F2特征,其中黄色特征代表1,紫色特征代表−1;(d)为二值卷积输出,即F3特征。从图中可以发现,因为RSign将特征映射为二值数据,无法保留特征重要程度信息,造成卷积网络特征获取能力下降,(d)中特征丢失大量信息。为了解决Sign函数带来的问题,文中引进较少的参数,改进网络结构并优化了Sign函数。

图 2 (a)输入图片;(b)卷积层输入特征;(c)二值化特征;(d)卷积重建后特征
Figure 2. (a) Input image;(b) Input features of convolution layer;(c) Binarized features; (d) Reconstructed features after convolution
-
2021年,GAO等人[16]对卷积神经网络中BatchNorm(BN)层进行了探究。其发现BN层的批次依赖性能够实现稳定的训练和更好的网络表示,但不可避免地忽略了实例之间的表示差异。为进一步优化BN层工作,GAO首先证明了输入特征的均值包含部分推理信息,但BN推理将均值信息删除。为利用特征均值信息,GAO提出了Representative Batch Normalization (RBN)引进了均值用于特征中心校准,使归一化中心随着输入图像变化而偏移。最后,作者还引进缩放校准使特征稳定分布。
传统BN计算如公式(3)~(5)所示,式中:
$X$ 为待校准特征;$E( * )$ 为期望计算;$Var( * )$ 为方差计算;$\varepsilon $ 为微小常量,$\gamma $ ,$\;\beta $ 为学习变量。$$ 中心化: {X_m} = X - E(X) $$ (3) $$ 缩放: {X_s} = \frac{{{X_m}}}{{\sqrt {Var(X) + \varepsilon } }} $$ (4) $$ 仿射变换: Y = {X_s}\gamma + \beta $$ (5) RBN为BN增加了中心校准以及缩放校准,如公式(6)~(9)所示。公式(6)中
$X$ 为输入特征,${w_m}$ 为学习变量,${K_m}$ 为${({k_0},{k_1},\cdots,{k_n})^{\rm{T}}}$ ,${k_i}$ 为各通道期望,即$ ({\mu }_{0}, {\mu }_{1},\cdots,{\mu }_{c}) $ 。公式(9)中,${w_v}$ ${w_b}$ 为学习变量,${K_s}$ 与${K_m}$ 相似,此处为各通道方差的集合。$$ 中心校准: {X_{cm(n,c,h,w)}} = {X_{(n,c,h,w)}} + {w_{m(n,c)}} \odot {K_{m(n,c)}} $$ (6) $$ 中心化: {X_m} = {X_{cm}} - E({X_{cm}}) $$ (7) $$ 缩放: {X_s} = \frac{{{X_m}}}{{\sqrt {Var({X_{cm}}) + \varepsilon } }} $$ (8) $$ \begin{split} \\ 缩放校准: {X}_{cs}={X}_{s}\cdot R({w}_{v}\odot {K}_{s}+{w}_{b}) \end{split} $$ (9) -
2020年,Zhuang[17]等人对迁移学习进行详细的总结。迁移学习将已有知识域称为源域,待学习知识域称为目标域,可用于解决目标域样本不足的问题。2014年,Bengio等人将ImageNet分为类别不重合的两个数据集,并使用预训练与微调方案,实现DNNs在图像分类任务中迁移学习任务。Zhuang[17]证明了对于相关性较强的两个任务,通过源域预训练网络,小样本目标域数据微调训练方式,可以将源域学习的通用特征迁移至目标域。同时,迁移后网络特征提取能力随预训练网络提取能力增强而增强。
-
文中研究目标为轻量化InGaAs近红外人脸检测网络。因为自主采集图像较少,同时互联网中相关波段开源人脸数据不足,文中无法建立完整近红外人脸数据集用于训练与测试。得益于近红外人脸特征与可见光下人脸特征相近,文中将采用迁移学习方案实现近红外人脸检测。
最终,ReActFace网络设计分为两个步骤:1) 通过网络中大规模可见光人脸数据训练由二值化特征提取网络和单精度预测网络组成的可见光二值化预训练网络;(2) 通过小样本近红外人脸数据对网络进行迁移学习,实现近红外二值化人脸检测网络。
-
基于SSD目标检测模型与ReActNet二值量化工作,文中首先实现了适应于可见光人脸检测的二值化卷积神经网络,并以此用作该工作的基准网络。为了解决基准网络中存在的特征学习能力不足的问题,文中接着提出了对抗卷积模块、带特征校准的Sign函数等方案加强了二值网络的学习能力。
ReActFace的总体设计基于SSD网络,如图3(a)所示,网络包括二值特征提取网络、提升网络感受野的附加卷积层以及卷积预测网络。网络以图像作为输入,返回人脸标记选框的尺寸和位置。其中,二值特征提取网络由图3(b)所示。
-
对于Sign函数而言,公式(1)中RSign函数为Sign函数增加了偏置
${\alpha _i}$ 。${\alpha _i}$ 是通过训练集数据获得的固定常量。与BN相似,RSign函数关注了数据的整体分布,但忽视了实例之间的差异。因为Sign函数在0处出现了突变,输入数据轻微波动将引入大量噪声,网络更关注实例间的差异。文中为RSign函数引入了输入特征均值作为实例信息,优化Sign函数判断。优化后的函数如公式(10)所示,文中命其为ARSign:$$ {X_s} = \left\{ {\begin{array}{*{20}{c}} { + 1}&{X + {w_s} \odot {\mu _m} \geqslant 0} \\ { - 1}&{X + {w_s} \odot {\mu _m} \lt 0} \end{array}} \right. $$ (10) 式中:
$X$ 为输入特征;${w_s}$ 为待学习参数。${\mu _m}$ 经过卷积层后的特征均值,即图3(b)中的Average Information。
图 3 (a)网络框图;(b)优化后的卷积模块框图
Figure 3. (a) Block diagram of network; (b) Block diagram of optimized convolution module
图4展示了ARSign工作效果。(1)为经过尺寸变换的输入图像,图中存在两条黄色虚线,分别为黄线1和黄线2。可以发现,黄线1没有包含人脸特征,而黄线2在竖向蓝线选中区域存在人脸特征。(2)为黄线1和黄线2处特征强度,其中,红线为特征经过RSign的输出,绿线为经过ARSign输出。左右两图分别为两个不同特征层示例。图表通过蓝线分割了人脸区域与非人脸区域、强度大于0的区域以及小于0的区域。通过ARSign函数,黄线1中非目标特征得到衰弱,使强度低于0,经过Sign函数后将被正确判断为不存在特征。而对于黄线2中的特征,ARSign函数进行增强,使更多人脸特征强度高于0,但同时也引进非目标特征噪声。总体而言,ARSign增强了特征信噪比,提升了检测效果。

图 4 (a)输入图像,(b)黄线处特征强度
Figure 4. (a) Input image; (b) Feature intensity at the yellow line
-
文中通过对抗卷积模块进一步增强了模型,增强后的网络结构如图3(b)中所示。相比于图1中ReActNet普通卷积模块与下采样模块,文中做了以下改进:
(1) 在ReActNet的基础上,引进了RBN替换了传统BN层,优化了网络标准化。
(2) 网络增加了ARSign->3×3 Conv->RBN的强化通路,用以学习困难对象特征。
(3)引进
$\alpha $ 参数,使两条通路实现对抗优化。进一步放大通路间的差异性。图5展示了输入图片后,对抗卷积模块中两条通路经过二值化后的特征图。(a)~(e)分别代表输入图片、输入卷积层的特征、特征经过RSign输出、经过ARSign输出及对抗卷积模块输出。从图中可以发现,RSign和ARSign提取了两组不同的特征。最终,对抗卷积层输出了更细致的纹理特征。

图 5 (a)输入图片;(b)卷积层输入特征;(c) ARSign通路二值化特征;(d) RSign通路二值化特征;(e)卷积重建后特征
Figure 5. (a) Input image;(b) Input features of convolution layer;(c) Binarized features of ARSign pathway;(d) Binarized features of RSign pathway;(e) Reconstructed features after convolution
-
经过可见光人脸图像预训练后的二值化人脸检测网络,将保留大量通用的人脸特征,以及少量可见光领域的偏移特征。由于用于微调的近红外人脸数据较少,为了更好的保留网络中通用的人脸特征,文中对网络微调学习率以及参与微调的网络层进行探究。
实验中首先固定了学习率,将预测层、附加网络和特征提取网络依次加入微调,最终发现仅固定特征提取网络获得最好的检测效果。固定更多或更少的网络将导致过拟合或欠拟合的问题,使检测准确度下降。对于学习率,通过探究设定为0.0002,并使微调训练循环次数设定在100。
-
文中使用WiderFace Dataset[18]训练集进行可见光人脸检测模型预训练。数据集包含32 203张图像并且标记了393 703张人脸,分类成为61种event。数据集中人脸在比例、姿势和遮挡方面具有高度可变性,并且将每一种event随机分成40%/10%/50%用作训练,验证以及测试集。WiderFace数据集以PASCAL VOC 2012方式标注以及储存。
WiderFace数据集依照图片中人脸的尺寸,角度等依据,将人脸数据集分为Easy,Medium与Hard三种类别。由于Test数据集需要提交WiderFace作者进行测试,本研究以WiderFace验证集测试模型训练效果。
实现模型训练及验证后,网络使用Face Detection Data Set and Benchmark(FDDB)[19]数据集进行测试。FDDB数据集包含了取自Labeled Faces in the Wild(LFW)[20]的一组2845张图片中的5171张面孔。
最后,文中使用InGaAs近红外摄像机采集了313张含612个人脸的近红外人脸图片,并将其1∶1分为迁移训练集与验证集进行训练以及测试。
-
实验使用一张RTX Titan 24 G显存的GPU进行训练,使用Pytorch实现网络。训练相关参数如下:
(1)输入图片尺寸:320×240
(2)网络训练采用随机梯度下降优化器(SGD)学习率为0.03,并在80, 100训练batch时降为0.003和0.0003。
(3)批量大小:36;
(4)训练循环次数:200;
(5)损失函数: CrossEntropyLoss;
(6)微调近红外网络时,批量大小为8,学习率为0.0002;
为提升网络鲁棒性,训练数据通过随机旋转、随机截取等方式模拟更多使用场景,实现数据增强[21]。
-
实验依次测试了ReactFace网络人脸检测准确率与网络压缩率。为了进一步测试各优化模块的实现效果,进行了模块消融实验。
实验结果中,Easy,Medium以及Hard表示WiderFace验证集中三种检测难度人脸的识别准确率。实验认为,预测框与真实选框IOU大于0.5被认为是判断正确,反之为错误。测试输入图像尺寸为320×240。FDDB数据集以ROC曲线展示实现效果。
-
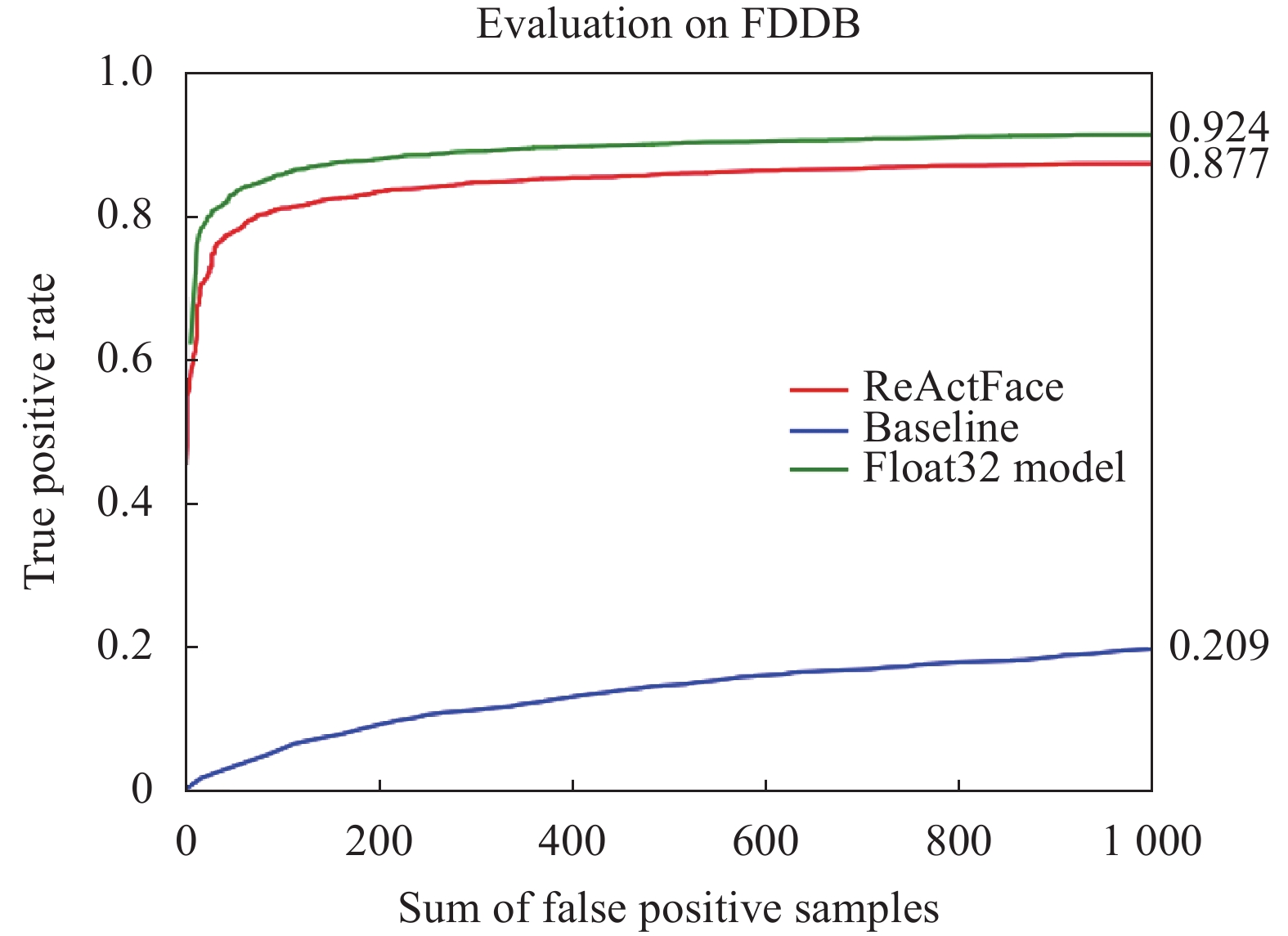
此节展示了ReActFace网络检测准确度结果,表1为WiderFace验证集测试结果,图6为FDDB测试集结果。其中,基准网络指将SSD网络通过ReActNet直接二值量化的网络,单精度SSD网络代表同结构的单精度人脸识别网络。

图 6 ReActFace在FDDB测试集中测试结果(Baseline指基准网络,Float32 Model指单精度SSD网络)
Figure 6. ReActFace test results in FDDB test set (Baseline refers to the benchmark network, Float32 Model refers to the full precision SSD network)
结合表1与图6,可以发现,ReActFace网络相较于基准网络网络检测准确度发生明显提升。对于WiderFace验证集,在Medium与Hard检测难度中,ReActNet与单精度网络仅有2.30%与3.48%的差距。对于FDDB人脸测试集,ReActFace网络仍保持了良好的鲁棒性,检测效果与单精度网络相近。
表 1 ReActFace在WiderFace验证集中测试结果
Table 1. ReActFace results in the WiderFace validation set
Net Easy mAP Medium mAP Hard mAP Baseline 66.38% 54.02% 23.45% ReActFace 71.19% 65.72% 37.29% Float32 SSD 76.48% 67.02% 40.77% -
依次将ARSign层替换为RSign,RBN替换为BN,并以单通路替换对抗卷积模块进行模块消融实验。表2展示了实验在WiderFace验证集中测试结果,图7展示了FDDB测试集测试结果。
表 2 模块消融实验在WiderFace验证集测试结果
Table 2. Module ablation results in the WiderFace validation set test
Net Easy mAP Medium mAP Hard mAP ReActFace 71.19% 65.72% 37.29% ReActFace-ARSign 71.00% 65.30% 37.00% ReActFace-RBN 70.90% 65.20% 36.62% ReActFace-Contrast Conv 65.50% 60.25% 33.72% Baseline 66.38% 54.02% 23.45% 
图 7 消融实验在FDDB中测试结果
Figure 7. Module ablation results in FDDB validation set test
从表2中可以发现各卷积模块对网络均产生了影响,其中,构建旁路的卷积对抗网络对提升网络准确率贡献最大。ARSign,RBN增强了网络对于中、困难样本学习。从图7中FDDB测试结果可以发现,在相同的误检样本的条件下,ReActFace能够保持更好的准确率。实验证明了ARSign、RBN函数与对抗卷积模块通过特征校准、构建对抗Sign通路等方式提升了二值网络在检测任务中特征提取能力。
-
表3展示了通过特征迁移学习后实现的近红外人脸检测网络测试效果。可以发现,ReActFace网络相比于基准网络检测准确度提升达7.46%。但是,单精度人脸检测网络经过迁移训练后,检测效果却不如ReActFace,文中推测复杂的卷积网络易于出现过拟合现象。单精度人脸检测网络相比于ReActFace学习了更多可见光下的特征而非通用人脸特征,导致迁移效果不如ReActFace。图8展示了ReActFace网络近红外人脸图片的检测效果。
表 3 近红外人脸数据集测试结果
Table 3. Result in NIR-Face data set
Net mAP Baseline 63.72% ReActFace 71.18% Float32 Face Detector 53.37% 
图 8 近红外人脸检测效果
Figure 8. Result on NIR Images
-
表4展示了网络二值量化后,特征提取网络与网络整体参数量变化。可以发现,二值量化后的特征提取网络实现了二倍以上压缩率。网络整体因为单精度预测层存在,网络参数下降了40%。特征提取网络中仍存在单精度保存的参数,可以通过8位整型量化,实现进一步压缩。
表 4 近红外人脸数据集测试结果
Table 4. Result in NIR-Face data set
Net Size of feature extractor/kb Size of Net/kb ReActFace 264.8 627.1 Float32 Face Detector 676.2 1040.8 -
文中对二值量化网络在近红外人脸检测领域应用进行了探究,依次完成单精度可见光人脸检测预训练网络、单精度网络二值量化与优化工作,以及近红外人脸微调工作。提出了特征校准ARSign二值函数,并通过对抗卷积模块提升了二值特征提取效果,最终网络被命名为ReActFace。ReActFace在WiderFace验证集和FDDB测试集中验证了预训练模型效果,在采集的近红外人脸数据集中获得71.18%平均检测准确度。未来,该研究将继续实现单精度网络二值量化工作,并使用FPGA进行硬件实现。
Research of ultra-light InGaAs NIR face detection algorithm
-
摘要: InGaAs近红外探测器广泛应用于航天航空、军事与民生领域。为了实现InGaAs探测器智能化,结合人脸检测应用,提出了可部署于低功耗移动智能设备的超轻量InGaAs近红外人脸检测算法。主要针对近红外人脸样本较少与低功耗设备部署问题展开研究,采用迁移学习与二值量化方案训练网络。算法首先通过大规模可见光人脸数据集实现了基于SSD的预训练人脸检测网络。然后使用二值量化方案大幅压缩网络参数空间大小与计算量,但同时造成网络准确度下降。为进一步提升网络二值量化效果,为二值量化过程引入了特征均值信息,并以对抗卷积形式弥补了准确度损失。最后,算法通过小规模近红外人脸数据对预训练二值网络进行微调,实现最终网络。所实现的二值量化人脸检测网络在采集的近红外人脸验证集中可以获得71.18%平均准确度。Abstract: InGaAs NIR detectors are widely used in aerospace, military and civilian fields. In order to realize the intelligence of InGaAs detectors, combined with face detection applications, an ultra-lightweight InGaAs NIR face detection algorithm that can be deployed in low-power mobile smart devices is proposed. This paper mainly studies the problems of few NIR face samples and low-power device deployment, and uses transfer learning and binary quantization to train the network. The algorithm first realizes a pre-trained face detection network based on SSD through a large-scale visible light face dataset. Then, the binary quantization scheme is used to greatly compress the network parameter space size and calculation amount, but the network accuracy is reduced at the same time. In order to further improve the effect of network binary quantization, this paper introduces feature mean information for the binary quantization process and makes up for the loss of accuracy in the form of adversarial convolution. Finally, the algorithm fine-tunes the pre-trained binary network through small-scale NIR face data to achieve the final network. The binarization face detection network implemented in this paper can achieve an average accuracy of 71.18% in the collected NIR face verification set.
-
Key words:
- binarization /
- NIR face detection /
- SSD /
- model compression /
- InGaAs detector
-
图 2 (a)输入图片;(b)卷积层输入特征;(c)二值化特征;(d)卷积重建后特征
Figure 2. (a) Input image;(b) Input features of convolution layer;(c) Binarized features; (d) Reconstructed features after convolution
图 3 (a)网络框图;(b)优化后的卷积模块框图
Figure 3. (a) Block diagram of network; (b) Block diagram of optimized convolution module
图 4 (a)输入图像,(b)黄线处特征强度
Figure 4. (a) Input image; (b) Feature intensity at the yellow line
图 5 (a)输入图片;(b)卷积层输入特征;(c) ARSign通路二值化特征;(d) RSign通路二值化特征;(e)卷积重建后特征
Figure 5. (a) Input image;(b) Input features of convolution layer;(c) Binarized features of ARSign pathway;(d) Binarized features of RSign pathway;(e) Reconstructed features after convolution
图 6 ReActFace在FDDB测试集中测试结果(Baseline指基准网络,Float32 Model指单精度SSD网络)
Figure 6. ReActFace test results in FDDB test set (Baseline refers to the benchmark network, Float32 Model refers to the full precision SSD network)
表 1 ReActFace在WiderFace验证集中测试结果
Table 1. ReActFace results in the WiderFace validation set
Net Easy mAP Medium mAP Hard mAP Baseline 66.38% 54.02% 23.45% ReActFace 71.19% 65.72% 37.29% Float32 SSD 76.48% 67.02% 40.77%  下载: 导出CSV
下载: 导出CSV
表 2 模块消融实验在WiderFace验证集测试结果
Table 2. Module ablation results in the WiderFace validation set test
Net Easy mAP Medium mAP Hard mAP ReActFace 71.19% 65.72% 37.29% ReActFace-ARSign 71.00% 65.30% 37.00% ReActFace-RBN 70.90% 65.20% 36.62% ReActFace-Contrast Conv 65.50% 60.25% 33.72% Baseline 66.38% 54.02% 23.45%
下载: 导出CSV
表 3 近红外人脸数据集测试结果
Table 3. Result in NIR-Face data set
Net mAP Baseline 63.72% ReActFace 71.18% Float32 Face Detector 53.37%
下载: 导出CSV
表 4 近红外人脸数据集测试结果
Table 4. Result in NIR-Face data set
Net Size of feature extractor/kb Size of Net/kb ReActFace 264.8 627.1 Float32 Face Detector 676.2 1040.8
下载: 导出CSV
-
[1] Xie Xingxing, Cheng Gong, Wang Jiabao, et al. Oriented r-cnn for object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021: 3520-3529. [2] Su Yunzheng, Hao Qun, Cao Jie, et al. Point cloud semantic segmentation method based on segmented blocks merging [J]. Infrared and Laser Engineering, 2021, 50(10): 20200482. (in Chinese) doi: 10.3788/IRLA20200482 [3] Li Weipeng, Yang Xiaogang, Li Chuanxiang, et al. An improved semi-supervised transfer learning method for infrared object detection neural network [J]. Infrared and Laser Engineering, 2021, 50(3): 20200511. (in Chinese) doi: 10.3788/IRLA20200511 [4] Zhang Shifeng, Chi Cheng, Lei Zhen, et al. Refineface: Refinement neural network for high performance face detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 43(11): 4008-4020. [5] Meng Qiang, Zhao Shichao, Huang Zhida, et al. Magface: A universal representation for face recognition and quality assessment[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 14225-14234. [6] Abdullah S M A, Ameen S Y A, Sadeeq M A, et al. Multimodal emotion recognition using deep learning [J]. Journal of Applied Science and Technology Trends, 2021, 2(2): 52-58. doi: 10.38094/jastt20291 [7] Wang Yunfeng, Li Zuopeng. Application research of object detection algorithm in edge environment [J]. Computer Engineering and Applications, 2021, 57(16): 220-228. (in Chinese) [8] Li Hao, Kadav Asim, Durdanovic Igor, et al. Pruning filters for efficient convnets [EB/OL]. (2016-08-31) [2022-03-09]. https://arxiv.org/abs/1608.08710. [9] Li Zhisheng, Wang Lei, Guo Shasha, et al. Laius: An 8-bit fixed-point CNN hardware inference engine[C]//2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), 2017: 143-150. [10] Courbariaux Matthieu, Hubara Itay, Soudry Daniel, et al. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or −1 [EB/OL].(2016-02-09)[2022-03-09]. https://arxiv.org/abs/1602.02830. [11] Krizhevsky Alex, Sutskever Ilya, Hinton Geoffrey E. Imagenet classification with deep convolutional neural networks [J]. Advances in Neural Information Processing Systems, 2012, 25: 1097-1105. [12] Liu Zechun, Shen Zhiqiang, Savvides Marios, et al. Reactnet: Towards precise binary neural network with generalized activation functions[C]//European Conference on Computer Vision, 2020: 143-159. [13] Liu Wei, Anguelov Dragomir, Erhan Dumitru, et al. Ssd: Single shot multibox detector[C]//European Conference on Computer Vision, 2016. SPRINGER: 21-37. [14] Ren Shaoqing, He Kaiming, Girshick Ross, et al. Faster r-cnn: Towards real-time object detection with region proposal networks [J]. Advances in Neural Information Processing Systems, 2015, 28: 91-99. [15] Howard Andrew G, Zhu Menglong, Chen Bo, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications [EB/OL]. (2017-04-17)[2022-03-09]. https://arxiv.org/abs/1704.04861v1. [16] Gao Shang-Hua, Han Qi, Li Duo, et al. Representative batch normalization with feature calibration[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 8669-8679. [17] Zhuang Fuzhen, Qi Zhiyuan, Duan Keyu, et al. A comprehensive survey on transfer learning [C]//Proceedings of the IEEE, 2020, 109(1): 43-76. [18] Yang Shuo, Luo Ping, Loy Chen-Change, et al. Wider face: A face detection benchmark[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 5525-5533. [19] Jain Vidit, Learned-Miller Erik. FDDB: A benchmark for face detection in unconstrained settings [R]. UMass Amherst Technical Report, 2010. [20] Huang Gary B, Mattar Marwan, Berg Tamara, et al. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments[C]//Workshop on Faces in 'Real-Life' Images: Detection, Alignment, and Recognition, 2008. [21] Shorten Connor, Khoshgoftaar Taghi M. A survey on image data augmentation for deep learning [J]. Journal of Big Data, 2019, 6(1): 1-48. doi: 10.1186/s40537-018-0162-3 -

 点击查看大图
点击查看大图
计量
- 文章访问数: 296
- HTML全文浏览量: 79
- PDF下载量: 61
- 被引次数: 0










































