







HTML
-
作为计算机视觉的研究方向之一,目标跟踪在视频监控、智能交通、军事制导、航天航空等领域都有广泛的应用。然而由于目标自身形变、旋转、运动模糊,以及外部应用场景光照变化、背景干扰、遮挡等因素的影响,建立一个高效稳健的目标跟踪算法依然面临着巨大的挑战。
随着深度学习方法在图像分类、目标检测等领域的应用取得了突破性的进展,研究者也逐步将其引入目标跟踪领域,利用深度卷积网络出色的特征表达能力提升算法的精度。HCF[1]利用预训练神经网络提取深层和浅层特征,并根据不同层的特点,分别训练相关滤波器,得到响应图加权融合,提升了跟踪精度。C-COT[2]通过连续空间域插值转换,将预训练神经网络提取的不同分辨率的特征图插值到连续空域,结合多分辨率的连续卷积滤波器进行训练和检测,取得了更加精确的定位。ECO[3]从滤波器系数、样本划分和模板更新策略三个方面进行优化,在保持跟踪精度的同时,大幅度提高了跟踪速度。相比传统手工特征,这类算法利用预训练深度特征结合相关滤波框架,可以提升算法的跟踪精度。但预训练深度模型大多是针对图像分类任务而设计,并未能较好地适应目标跟踪。同时,越来越高的特征维度,给在线学习、更新过程带来了巨大的计算开销,直接限制了算法的跟踪速度。
深度学习方法在目标跟踪领域的应用不仅局限于预训练深度特征,为了利用端到端的优势,研究者们开始引入Siamese框架,训练专门的端到端跟踪网络。SINT[4]开创性地引入Siamese网络,将目标跟踪任务转化为相似性学习问题,学习一个匹配函数。在跟踪过程中将后续帧的候选框与第一帧目标框进行匹配度计算,得分最高的即为目标。通过使用涵盖了各种目标变化可能情况的大规模训练数据集离线训练模板匹配网络,在不应用任何模型更新,没有遮挡检测,没有跟踪器的组合,没有几何匹配的情况下实现目标跟踪。SiamFC[5]针对跟踪任务使用大规模视觉图像识别比赛中的视频离线训练一个深度网络,跟踪过程对候选图像进行全卷积,通过计算其两个输入互相关的双线性层完成滑窗在线评估,在保证高准确率的同时,速度也远超实时性。CFNet[6]将相关滤波转换为可微分的神经网络层,联合特征提取网络实现端到端的优化,训练与相关滤波器匹配的卷积特征,学习变换背景矩阵与目标外观矩阵,达到适应目标变化以及抑制背景变化的目的。SiamRPN[7]引入区域候选网络通过边界框回归代替多尺度检测,网络结构包括特征提取的 Siamese子网络和产生候选目标区域的RPN子网络。通过将Siamese子网络模板分支、检测分支的特征同时输入到RPN子网络的分类分支与回归分支,将跟踪问题转换成为单次学习匹配问题。DasiamRPN[8]从训练数据不平衡、自适应的模型增量学习及长时跟踪等方面对算法进行了优化,在目标遮挡和长时跟踪等情况下表现突出。
尽管基于Siamese网络的端到端跟踪算法在通用数据集中取得了卓越的跟踪效果,但仍存在一些问题。离散训练网络只学习到了目标的通用特征,若在线跟踪过程中目标周围出现相似干扰物,则无法进行判断。在线跟踪的目标很可能并未包含在离线训练数据集中,那么相似性度量的结果未必可靠。由于特征提取与判别功能耦合在同一个网络里,缺少了分类器的在线训练环节,导致网络的适应能力、判别能力较弱。文中提出一种端到端的目标跟踪算法,承继Siamese网络架构的特点,选取更深的卷积网络模型VGG-Net-16[9]作为主干网络,使模型具有更强的特征表达能力;探索多种注意力机制,包括通道注意力、互联注意力以及空间注意力,使离线训练的模型在线跟踪时具有更优越的适应能力以及判别能力;通过加权融合响应得分图,以获取更精准的定位;在大规模数据集上离线训练端到端网络。在目标跟踪通用数据集中,进行算法性能的验证,与当前主流算法相比,文中算法在保证实时性的前提下,能够取得良好的跟踪精度。
-
Siamese网络结构[10]最早提出用于验证支票上的签名是否与银行预留的签名一致,后来Sergey Zagoruyko[11]等将其引入进行图像相似度的计算。
如图1所示,Siamese网络结构通常由结构相似、权值共享的两个分支构成。将两个图片
${{{X}}_1}$ 、${{{X}}_2}$ 分别输入两个分支,通过构建一种函数${{{G}}_{\rm{w}}}\left( {{X}} \right)$ 将其映射到特征空间,得到两个特征向量${{{G}}_{\rm{w}}}\left( {{{{X}}_1}} \right)$ 、${{{G}}_{\rm{w}}}\left( {{{{X}}_2}} \right)$ ,使用一种距离度量${{{E}}_{\rm{w}}}\left( {{{{X}}_1},{{{X}}_2}} \right)$ ,作为两张图片的相似度计算函数,衡量二者之间的差异。
Figure 1. Framework of Siamese network
-
近年来,在深度学习的发展推动下,Siamese网络被应用于目标跟踪领域,并取得了令人瞩目的成绩。基于Siamese网络的代表性跟踪算法SiamFC[5]提出,将目标跟踪任务转化为相似性度量问题,利用大量样本数据离线训练一个Siamese网络(由卷积层、非线性激活层和池化层构成),将视频序列第一帧作为模板分支的输入图像
${{\textit{z}}}$ ,后续帧中的候选区域作为检测分支的输入图像${{x}}$ ,分别通过权值共享的特征提取网络$\varphi \left( \cdot \right)$ ,将原始图像映射到特定的特征空间,学习一个度量函数$f(z,x)$ ,如公式(1)所示,用于比较模板图像和候选区域搜索图像之间的相似度,返回响应图,分数越高,二者相似度越高。其中$ * $ 代表互相关运算,$b \cdot {{I}}$ 表示在响应图中每个位置的取值。 -
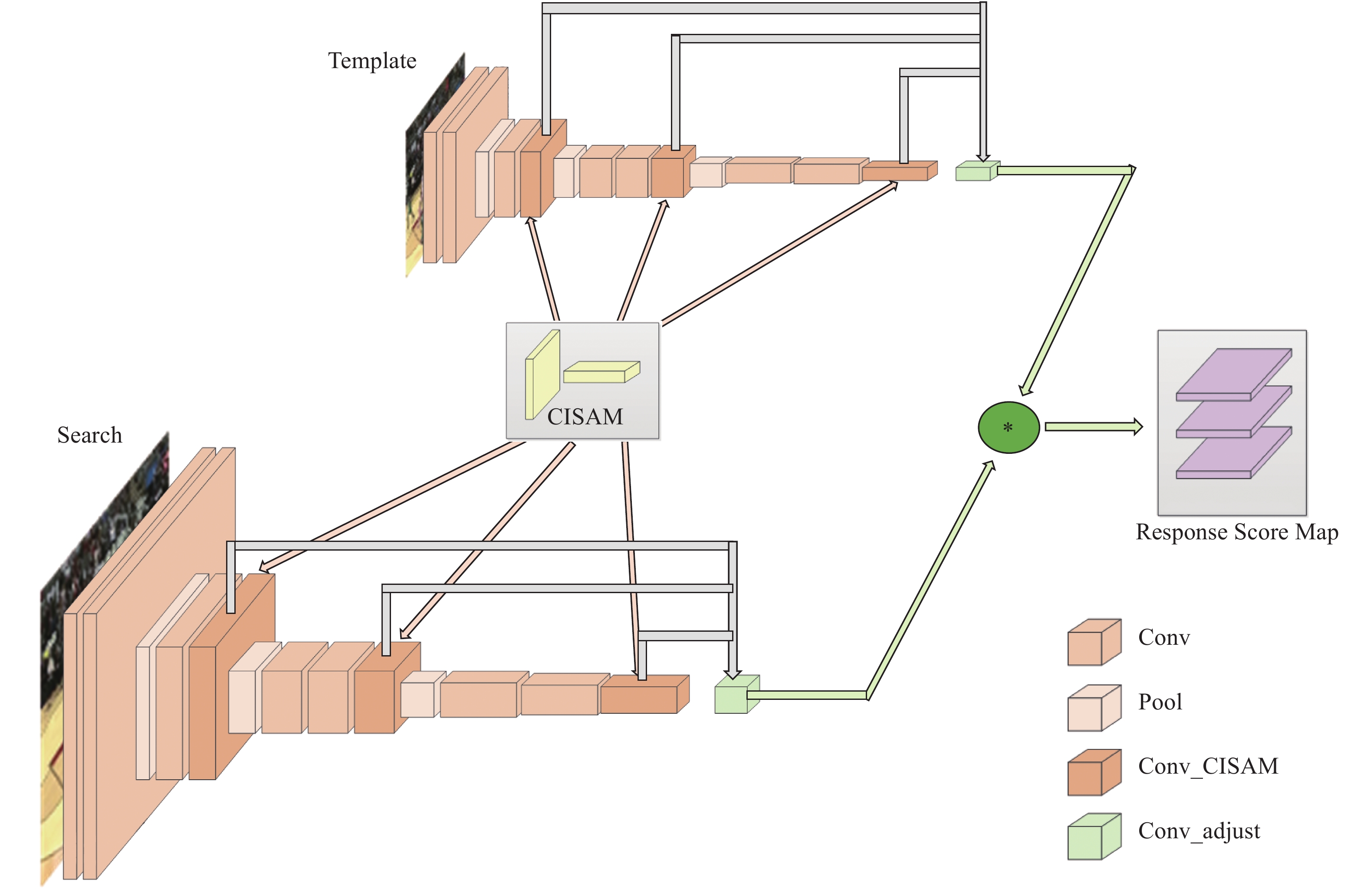
算法框架如图2所示。
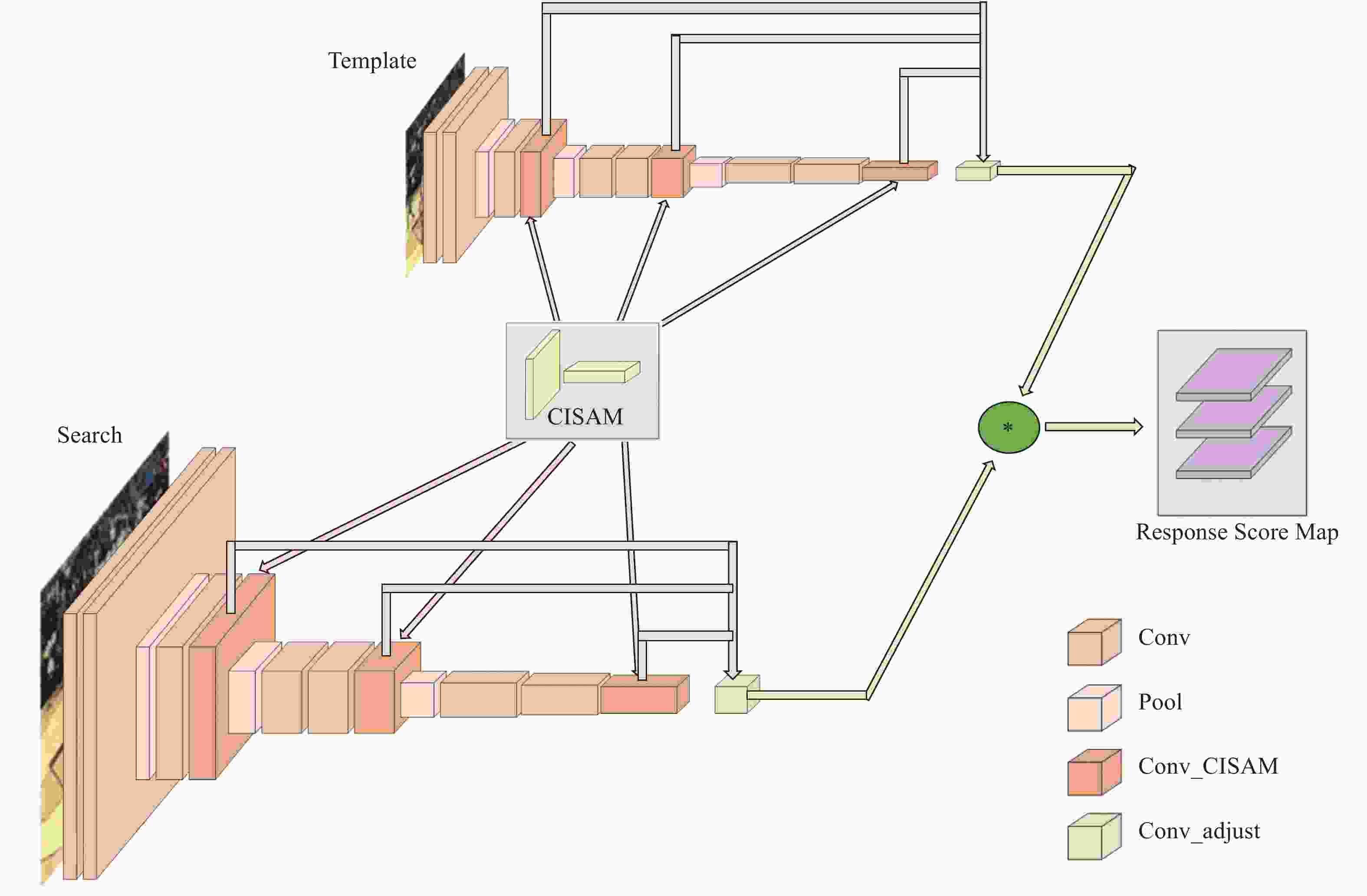
Figure 2. Framework of algorithm
主要包括Siamese深度网络、通道-互联-空间注意力模块(Channel-Interconnection-Spatial Attention Module,CISAM)、互相关运算以及响应得分图融合四部分组成。其中Siamese深度网络基于VGG-Net-16进行构建,再融入CISAM。图像序列经过改进后的Siamese网络,将原始图像映射到特定的特征空间,得到多层特征图,分别进行互相关运算,输出响应得分图(Response Score Map)进行融合,得分越高,则相应位置是目标的概率越大。
-
特征提取是决定跟踪算法性能的最关键因素[12]。为了提升网络的特征提取能力,而又不引入填充破坏网络的平移不变性,文中网络基于适应能力更强的VGG-Net-16进行构建。
VGG-Net-16是由3×3的小型卷积核以及2×2的最大池化层反复堆叠构筑而成的卷积神经网络,通过小型卷积核的深度复用模拟较大卷积核完成对图像的局部感知,提升网络的性能。模型主要由5段卷积、2个全连接特征层以及1个全连接分类层组成。VGG-Net-16能够提取到非常丰富的特征,将其提取到的不同层不同通道的部分特征图可视化,如图3所示。

Figure 3. A set of feature maps extracted by VGG-Net-16
为了将VGG-Net-16更好地运用到文中所提算法中,根据Siamese网络的特点,同时考虑到后续互相关以及响应图的融合等操作,对VGG-Net-16进行修改,具体网络结构如表1所示。从表中可以看出,修改主要包括以下四个方面。
(1)删减:考虑到目标跟踪任务对精细位置的需求,删除第五段卷积,缩小了网络模型的总步长;
(2)增加:在网络模型内,在卷积层Conv2_2、Conv3_3、Conv4_3后均融入了通道-互联-空间注意力模块CISAM,形成特征图层Conv_CISAM,尺寸维持不变,分别记作Conv2_2_CISAM、Conv3_3_CISAM以及Conv4_3_CISAM;
(3)提取:为了利用多分支特征协同进行定位,将Conv2_2_CISAM、Conv3_3_CISAM以及Conv4_3_CISAM分别提取;
(4)调整:为了便于后续响应得分图计算时的融合,在进行互相关运算前,将多分支特征Conv2_2_CISAM、Conv3_3_CISAM以及Conv4_3_CISAM分别输入调整层Conv_adjust进行调节。
Layer name Kernel size Chan. map Template size Search size Channel output Stride CISAM Input 127×127 255×255 3 - No Conv1_1 3×3 64×3 125×125 253×253 64 1 No Conv1_2 3×3 64×64 123×123 251×251 64 1 No Pool1 2×2 61×61 125×125 64 2 No Conv2_1 3×3 128×64 59×59 123×123 128 1 No Conv2_2 3×3 128×128 57×57 121×121 128 1 Yes Pool2 2×2 28×28 60×60 128 2 No Conv3_1 3×3 256×128 26×26 58×58 256 1 No Conv3_2 3×3 256×256 24×24 56×56 256 1 No Conv3_3 3×3 256×256 22×22 54×54 256 1 Yes Pool3 2×2 11×11 27×27 256 2 No Conv4_1 3×3 512×256 9×9 25×25 512 1 No Conv4_2 3×3 512×512 7×7 23×23 512 1 No Conv4_3 3×3 512×512 5×5 21×21 512 1 Yes Table 1. Architecture of Siamese network
-
仅仅增加网络的深度只能相对提升特征表达能力,并不能从根本上解决Siamese框架存在的问题。因为相对于相关滤波类的跟踪算法,基于Siamese网络的跟踪算法缺少了分类器的在线训练环节,在同一个网络中耦合了特征提取与判别功能。这需要网络同时具备两种特质:一是能够稳定地适应目标自身在各种场景中的变化,抽象出目标代表性、本质性的特征;二是能够敏感地区分目标及相似物,显著地提炼出二者之间的差异。
设经过Siamese主干网络提取到的特征图分别为
$\varphi \left( {{\textit{z}}} \right) \in {\mathbb{R}^{C \times {H_{\rm{T}} } \times {W_{\rm{T}} }}}$ 、$\varphi \left( {{x}} \right) \in {\mathbb{R}^{C \times {H_{\rm{D}} } \times {W_{\rm{D}} }}}$ ,其中,$C$ 为通道数,${H_{\rm{T}}}$ 、${H_{\rm{D}}}$ 为特征图在垂直方向的尺寸,${W_{\rm{T}}}$ 、${W_{\rm{D}}}$ 为特征图在水平方向的尺寸,${H_{\rm{T}} } \leqslant {H_{\rm{D}} }$ 、${W_{\rm{T}} } \leqslant {W_{\rm{D}} }$ ,二者进行互相关运算得到的$f({{\textit{z}}},{{x}}) \in {\mathbb{R}^{C \times {H_f} \times {W_f}}}$ ,其中响应图垂直方向、水平方向的尺寸分别为${H_f} = {H_{\rm{D}} } - {H_{\rm{T}} } + 1$ 、${W_f} = $ $ {W_{\rm{D}} } - {W_{\rm{T}} } + 1$ ,$b$ 为响应图中每个位置的权值。将Siamese网络的匹配函数公式(1)展开如公式(2)所示:可以看到,互相关的计算过程对特征图的通道层面、空间层面的关注度非常平均,权重系数均为1。事实上在跟踪任务中,不同通道、不同位置的特征重要性是不同的。研究表明[13],注意力机制在人类视觉过程中起到重要作用,图像中的高层语义特征能够吸引人类的视觉注意力。因此,可以借鉴性地引入注意力机制弱化贡献度小的特征图,强化贡献度大的特征图,关注目标前景和语义背景的差异特征,实现对目标的增强、对干扰的抑制以及对不同对象间的判别,提高复杂场景下算法的稳健性与实时性。为此,选择在特征提取主干网络的卷积层中融入注意力模块,通过调节权重参数突出或筛选目标的重要信息,抑制无关的细节信息,提升网络的判别能力,获得相当于分类器在线学习的功能。
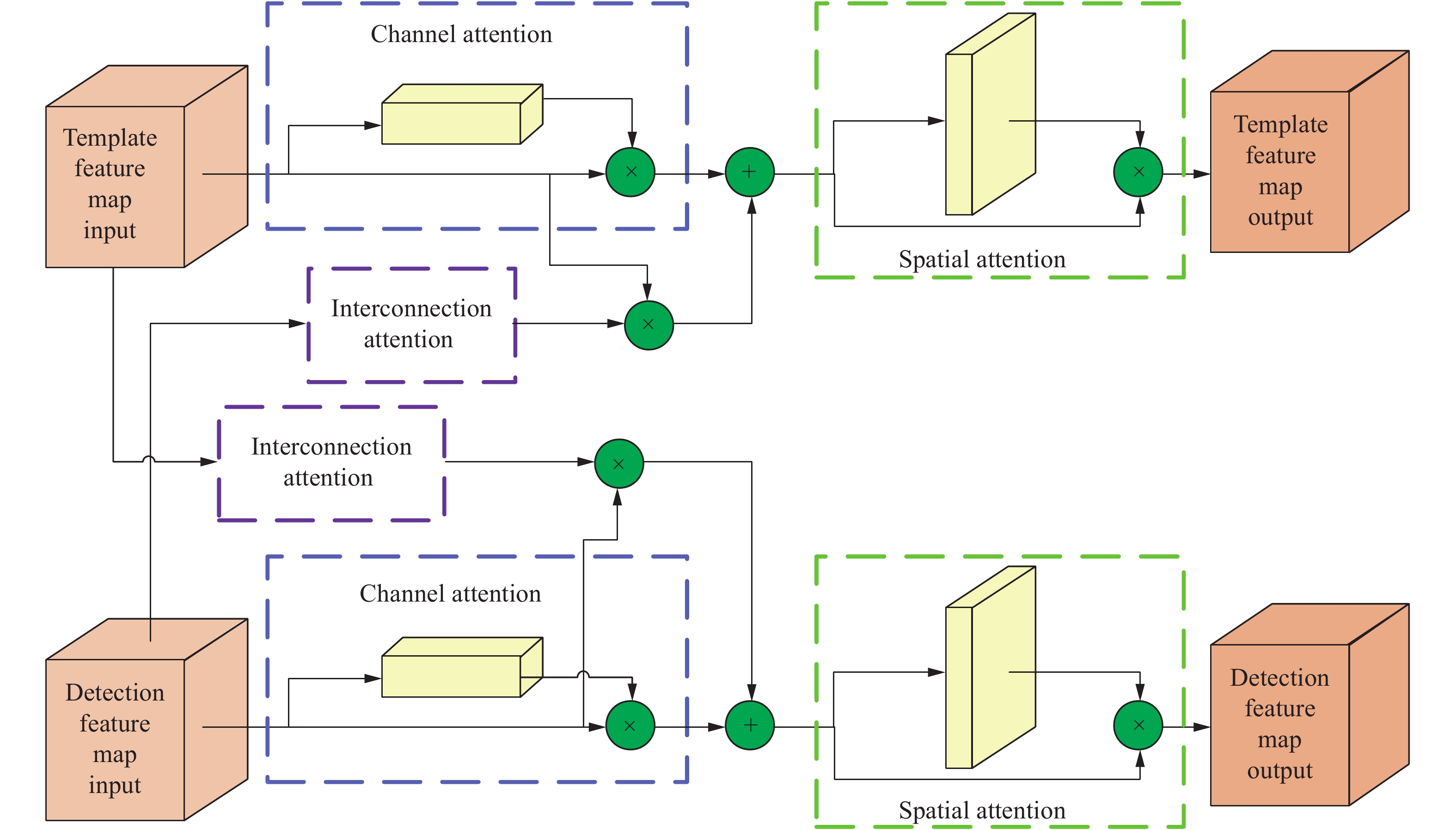
CBAM[14]提出将注意力机制同时运用在通道和空间两个层面,可以嵌入目前大部分主流深度网络,在不显著增加计算量和参数量的前提下能提升网络模型的特征提取能力。考虑到Siamese网络的结构特点,文中在此基础上,加入了互联注意力模块,形成通道-互联-空间注意力模块CISAM,具体结构如图4所示。
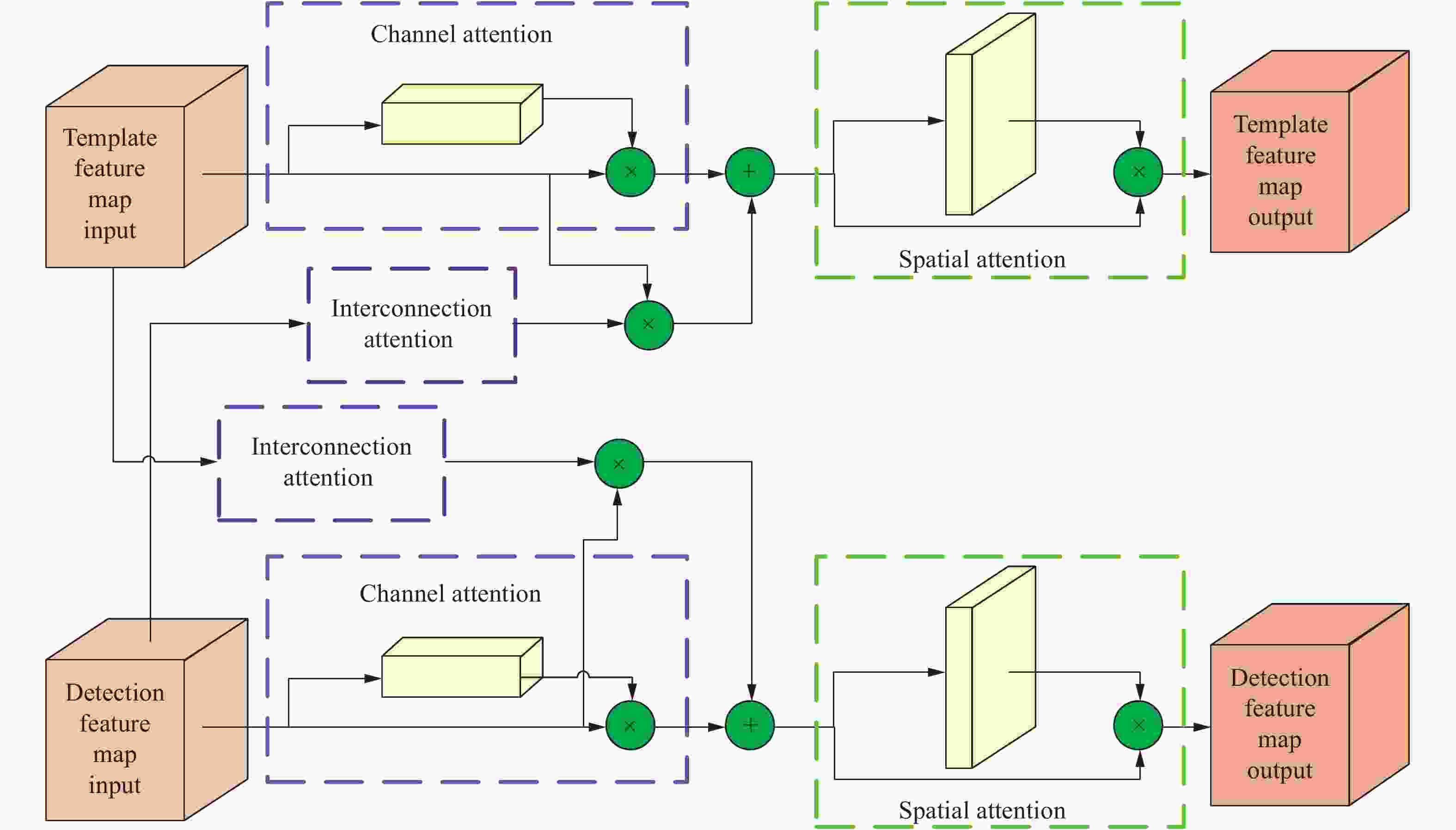
Figure 4. Structure of CISAM
模板分支、检测分支卷积层输出的特征图
$\varphi \left( {{\textit{z}}} \right)$ 、$\varphi \left( {{x}} \right)$ ,经过通道注意力模块得到注意图${{{A}}_{\rm C}}\left\{ \cdot \right\} \in {\mathbb{R}^{C \times 1 \times 1}}$ ,通过公式(3)、(4)分别输出通道特征图${\varphi _{{\rm C}} }\left( {{\textit{z}}} \right)$ 、${\varphi _{{\rm C}} }\left( {{x}} \right)$ ,$ \otimes $ 表示元素点乘。通道注意力模块对输入特征图在空间维度进行压缩,同时使用全局平均池化与全局最大池化,前者对特征图上的每一个像素点都进行反馈,而后者对全局平均池化进行补充。每个通道等价为一个不同类型的特征判别器,从语义层面对特征优化选择,激活与目标相关程度更高的,删除冗余的通道特征。
同时,模板分支、检测分支卷积层输出的特征图
$\varphi \left( {{\textit{z}}} \right)$ 、$\varphi \left( {{x}} \right)$ ,经过互联注意力模块得到注意图${{{A}}_{\rm I}}\left\{ \cdot \right\} \in {\mathbb{R}^{C \times C}}$ ,由于两个分支的空间尺寸并不相同,进行互联时需要先调整维度,得到${\varphi _{{\rm{RS}} }}\left( {{\textit{z}}} \right) \in {\mathbb{R}^{C \times {P_{\rm{T}} }}}$ 、${\varphi _{{\rm{RS}} }}\left( {{x}} \right) \in {\mathbb{R}^{C \times {P_{\rm{D}} }}}$ ,其中${P_{\rm{T}} } = {H_{\rm{T}} } \times {W_{\rm{T}} }$ 、${P_{\rm{D}} } = {H_{\rm{D}} } \times {W_{\rm{D}} }$ ,通过公式(5)、(6)分别输出互联特征图${\varphi _{{\rm{I}} {\rm{RS}} }}\left( {{\textit{z}}} \right)$ 、${\varphi _{{\rm{I}} {\rm{RS}} }}\left( {{x}} \right)$ 。再调整恢复维度后输出互联特征图${\varphi _{\rm{I}} }\left( {{\textit{z}}} \right)$ 、${\varphi _{\rm{I}} }\left( {{x}} \right)$ 。互联注意力模块将两个分支分别编码至另外一个分支,可以帮助结合目标及其背景之间的相关性。两个分支的通道注意力与互联注意力分别汇合后,再经由空间注意力模块得到注意图
${{{A}}_{\rm S}}\left\{ \cdot \right\} \in {\mathbb{R}^{1 \times {H_{\rm{T}} } \times {W_{\rm{T}} }}}$ 、${{{A}}_{\rm S}}\left\{ \cdot \right\} \in {\mathbb{R}^{1 \times {H_{\rm{D}} } \times {W_{\rm{D}} }}}$ ,通过公式(7)、(8)融合提取出特征图${\varphi _{\rm{S}} }\left( {{\textit{z}}} \right)$ 、${\varphi _{\rm{S}} }\left( {{x}} \right)$ :空间注意力模块使用全局平均池化与最大池化对输入特征图在通道层面进行压缩,得到两个二维的特征图,并拼接得到一个通道数为2的特征图,经由隐藏层对其进行卷积操作,保证特征图在空间维度上保持不变。空间注意力更集中于位置的描述,与通道注意力的相互补充,通过构建特征图中不同位置之间的联系,从空间层面学习特征图的哪些部分应该会有更高的响应,针对位置进行加权融合。
-
充分利用不同层次的特征图,能够提升跟踪性能。浅层特征空间分辨率较高,纹理信息全面,易于定位目标,能够防止表观相似的干扰背景。深层特征语义信息丰富,能够稳定适应目标形变、遮挡等表观变化。为了降低复杂场景中干扰源的影响,获取高质量的响应得分图,采用多层特征融合的方法。首先将CISAM输出的特征图通过调整层将通道数统一调整为256;接着分别计算模板分支与检测分支中各调整层输出的第
$q$ 层特征进行互相关运算;最后将响应得分图以加权的方式进行融合,如公式(9),其中${\alpha _q}$ 为第$q$ 层的权重参数。综合分析响应得分图,确定参数的具体值。 -
(1) 数据集的准备
训练集中的数据选自ImageNet VID[15]、COCO[16]和Youtube-bb[17],通过特定的比例组合。从相同的视频序列中随机选取两帧,并将它们组合成一对模板图像(127×127)和搜索图像(255×255),作为Siamese网络的输入。
为保证所有的输入图像均为正方形,按照公式(10)调整,其中
$\left( {w,h} \right)$ 为原始目标框尺寸,$p$ 为上下文边距,$s$ 为尺度变换因子,$A = {127^2}$ 。正样本定义为响应得分图中的元素
$u$ 在响应得分图中心$c$ 的搜索区域半径$R$ 内,其余的视作负样本,$k$ 为全卷积网络的总步长。文中设定$R = 2$ ,$k = 1$ 。(2) 网络模型的搭建
按照表1定义的网络结构进行网络模型的搭建,按照VGG-Net-16预训练模型进行初始化。
(3) 损失函数与优化器的选择
损失函数采用逻辑回归损失函数,如公式(12)所示:
式中:
$y \in \left\{ { + 1, - 1} \right\}$ 代表候选样本对对应的标签值;$v$ 代表单个图像样本对的实际相似计算得分值。整体响应图的损失函数定义为全部点的损失函数的均值,可表示为:式中:
$D$ 为响应得分图中像素数目;$u \in D$ 为响应得分图各个位置;$v\left[ u \right]$ 为每个位置的互相关卷积计算值各个搜索位置$u$ 的响应得分;$y\left[ u \right]$ 代表响应得分图各个位置的真值标签正负样本的划分。最小化目标函数如公式(14)所示,模型参数
$\theta $ 指代的是网络的各层参数,采用随机梯度下降(SGD)对网络参数进行优化,从而得到网络参数的最优值,使其具有识别输入样本对特征共通性的能力。(4)网络训练
训练时学习率设置为10−3~10−6。整个训练过程包含100多个阶段,每个阶段由6000对样本组成。每次计算8对样本的平均损失值。
-
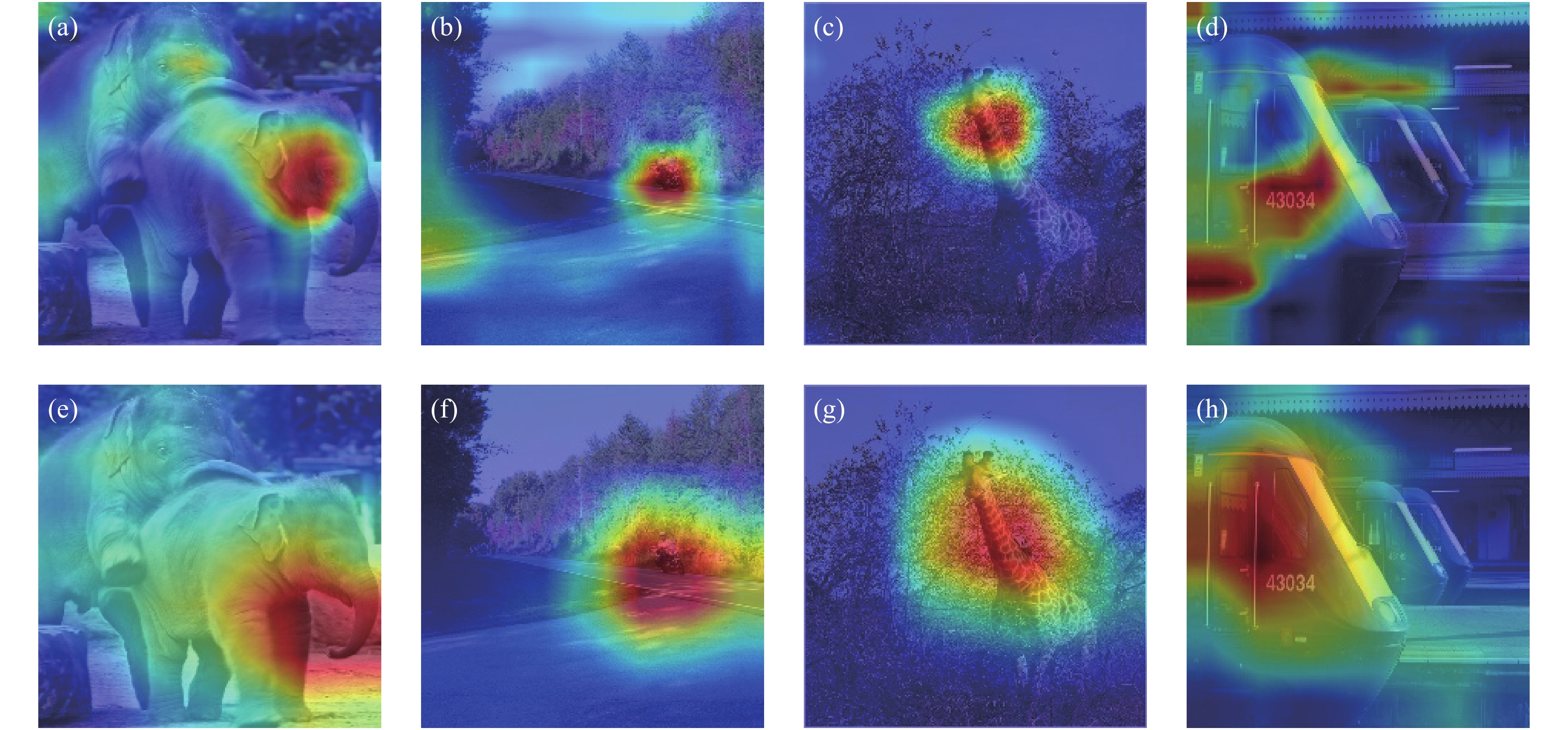
为分析文中通道-互联-空间注意力模块CISAM的作用,利用类激活热力图Grad-CAM[18]对不同的网络进行可视化,如图5所示。越敏感的位置温度越高,越不敏感的位置温度越低。第一排是未加CISAM的网络模型可视化结果,第二排是加入CISAM后的网络模型可视化结果。实验结果可以看出添加CISAM模块的网络的注意范围更广,能够更好地覆盖到所要识别的物体。当周围有相似物出现时,能更好地进行区分,将注意力集中在目标上,并未受到相似物体的干扰。

Figure 5. Grad-CAM network visualization results
-
文中所提跟踪算法的实验平台硬件配置如表2所示。
Device Product model Memory CPU Intel(R)Core(TM)i7-9700 16G Basic frequency 3.0 GHz GPU NVIDIA GeForce RTX-2060 6G Table 2. Experimental platform parameters
算法基于Pytorch实现,选择当前具有代表性的六种算法,包括文中所提算法、ECO[3]、SiamFC[5]、CFNet[6]、SiamRPN[7]、DasiamRPN[8],在目标跟踪通用数据集OTB-2015[19](涵盖11个属性,共100组视频)上测试评估算法的性能。以一次通过评估OPE (One Pass Evaluation)作为跟踪算法准确性能的评价标准。
-
六种算法在数据集部分视频序列中的跟踪结果,如图6所示。不同算法的目标框使用不同的颜色表示,其中文中算法用红色表示。

Figure 6. Qualitative results display of the 6 tracking algorithms over partial video sequences
图6(a) CarDark序列中,目标时而变模糊,时而被遮挡,周围存在相似类干扰,同时光照情况也不断发生变化,文中算法由于可以筛选出适应性更强的目标特征,区分背景,所以始终未发生漂移。
图6(b) MotorRolling序列中,目标自身发生超过360°的旋转,对特征表达能力提出了极大的挑战,除文中所提算法、SiamRPN以及DasiamRPN,其他算法在跟踪初始已经偏离了目标。
图6(c) Skating1序列中,光照不断发生变化,且目标周围不断出现相似类干扰,多数算法已经远离目标,只有文中算法、SiamRPN以及ECO准确定位。
图6(d) Skiing序列中,目标尺寸较小且速度较快,这对特征提取提出了更严格的要求,特征提取能力或者匹配能力低的算法在跟踪初始已经无法定位目标。
图6(e) Suv序列中,目标清晰度低,偶尔超出视野范围,文中算法表现稳健,能够保持跟住目标。
图6(f) Walking2序列中,目标尺度变化,中间偶有被遮挡,且有相似类干扰出现,文中算法能够避免遮挡出现时,跟踪漂移。
通过对以上涵盖属性较为丰富的视频序列进行分析,文中所提算法在光照变化、尺度变化、旋转、相似物干扰、快速运动、分辨率低、超出视野等情况均有极佳的表现。
-
跟踪算法主要通过对中心位置误差和覆盖率两个指标进行评估。前者是指跟踪结果与真实目标的中心位置之间的欧式距离;后者是指跟踪结果与真实目标的重叠率,均通过一定的阈值判定跟踪是否成功。二者分别体现在精度图以及成功率图中。
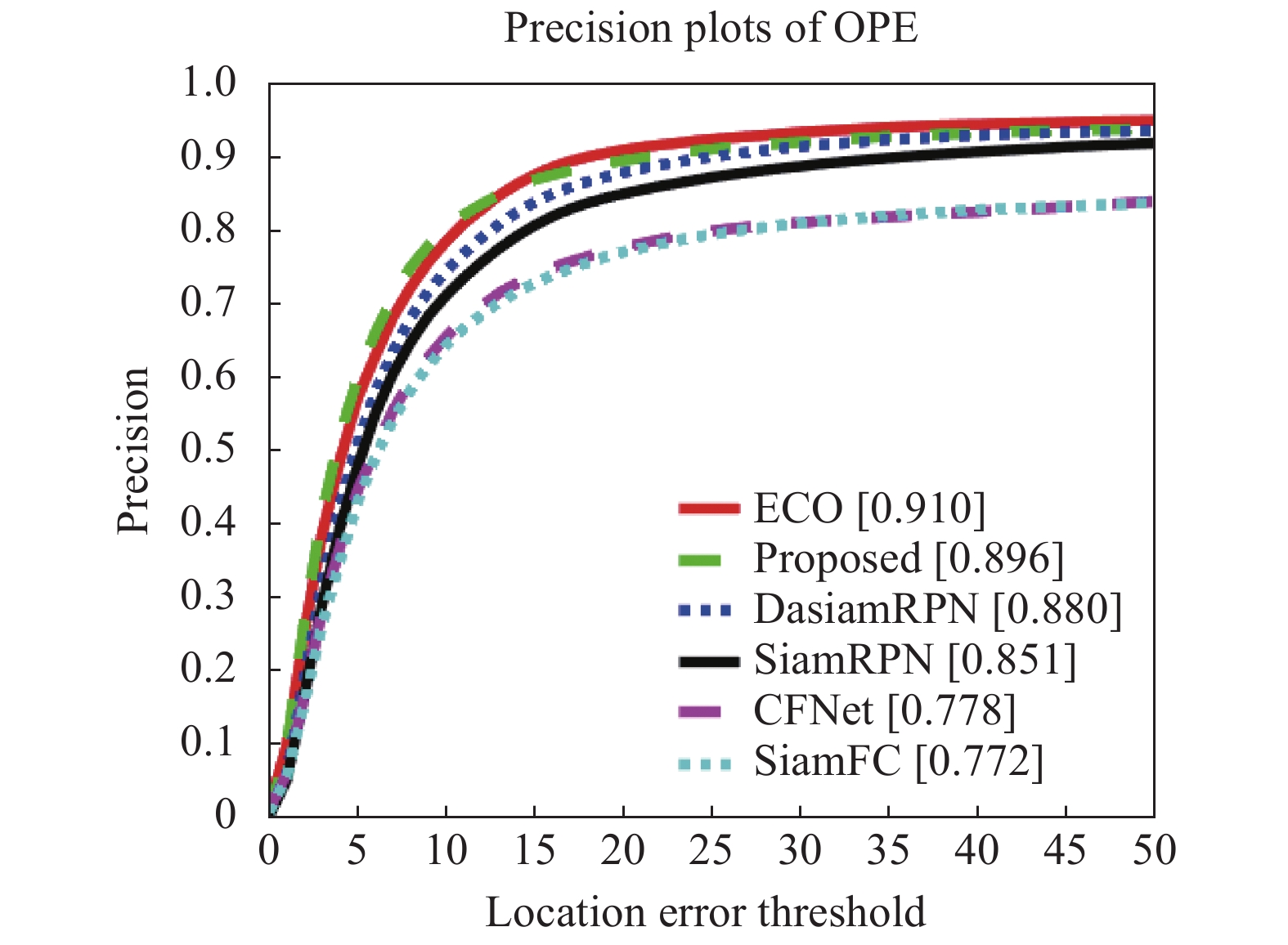
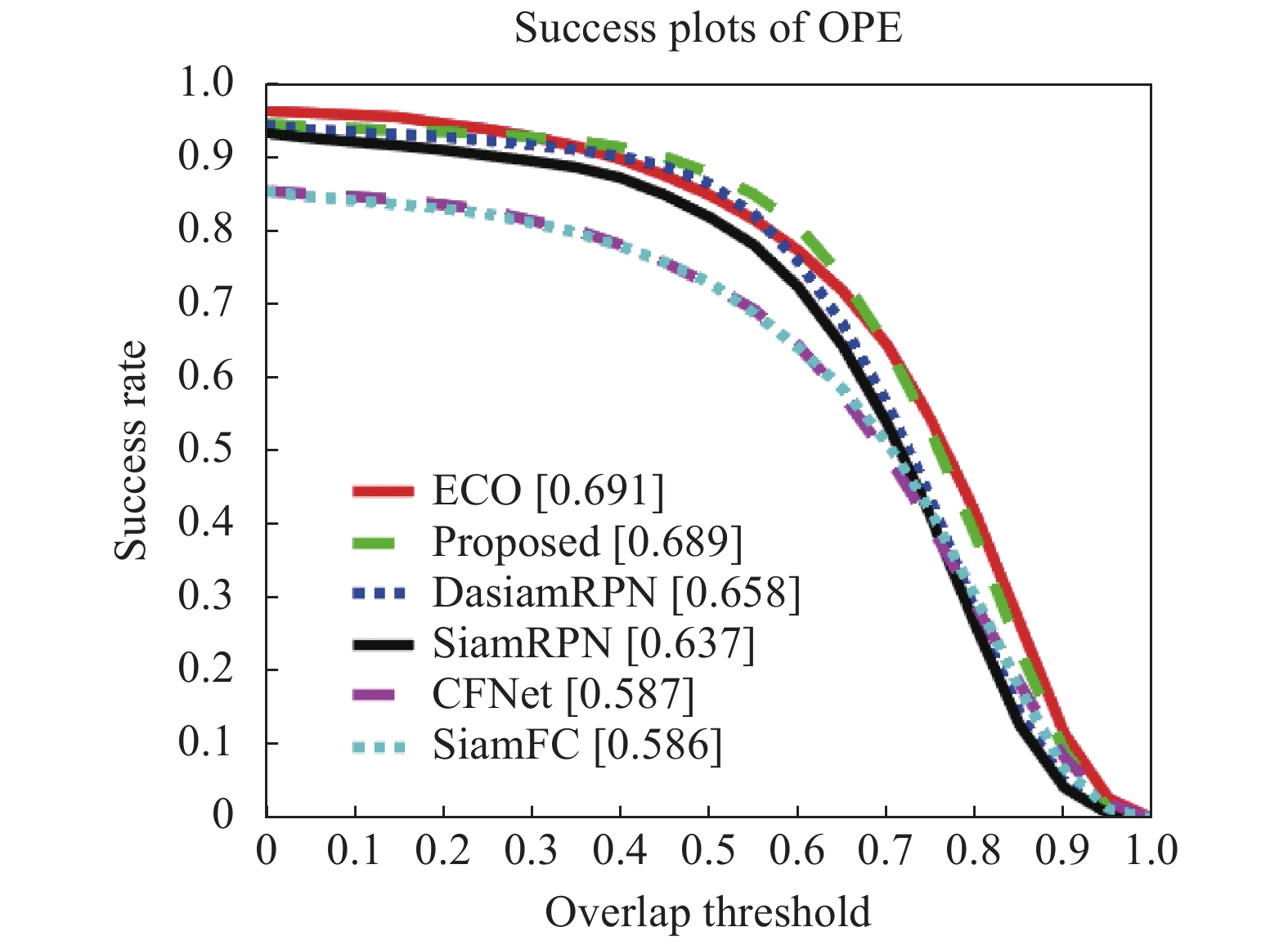
(1)六种算法在OTB-2015上的跟踪精度曲线以及成功率曲线分别如图7、图8所示。文中算法跟踪精度达到0.896,成功率为0.689,相对于SiamFC算法分别提高了12.4%、10.3%。证明文中算法在Siamese网络框架的基础上,提取了更深的网络特征,同时融入了注意力模块,使得网络提取到适应能力更强的特征,提升了算法的总体精度与稳健性。
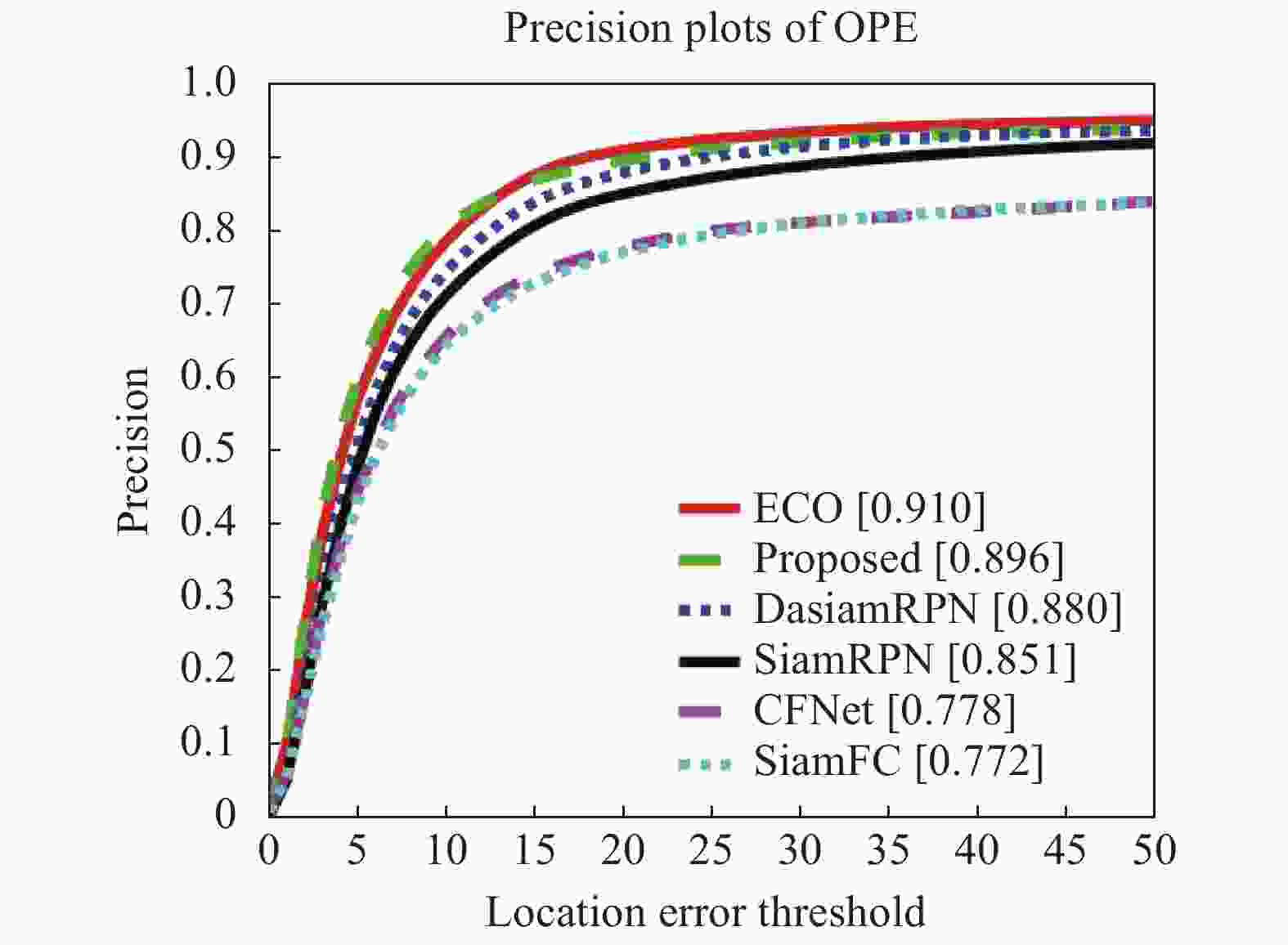
Figure 7. Tracking precision plots of OPE on OTB-2015 dataset
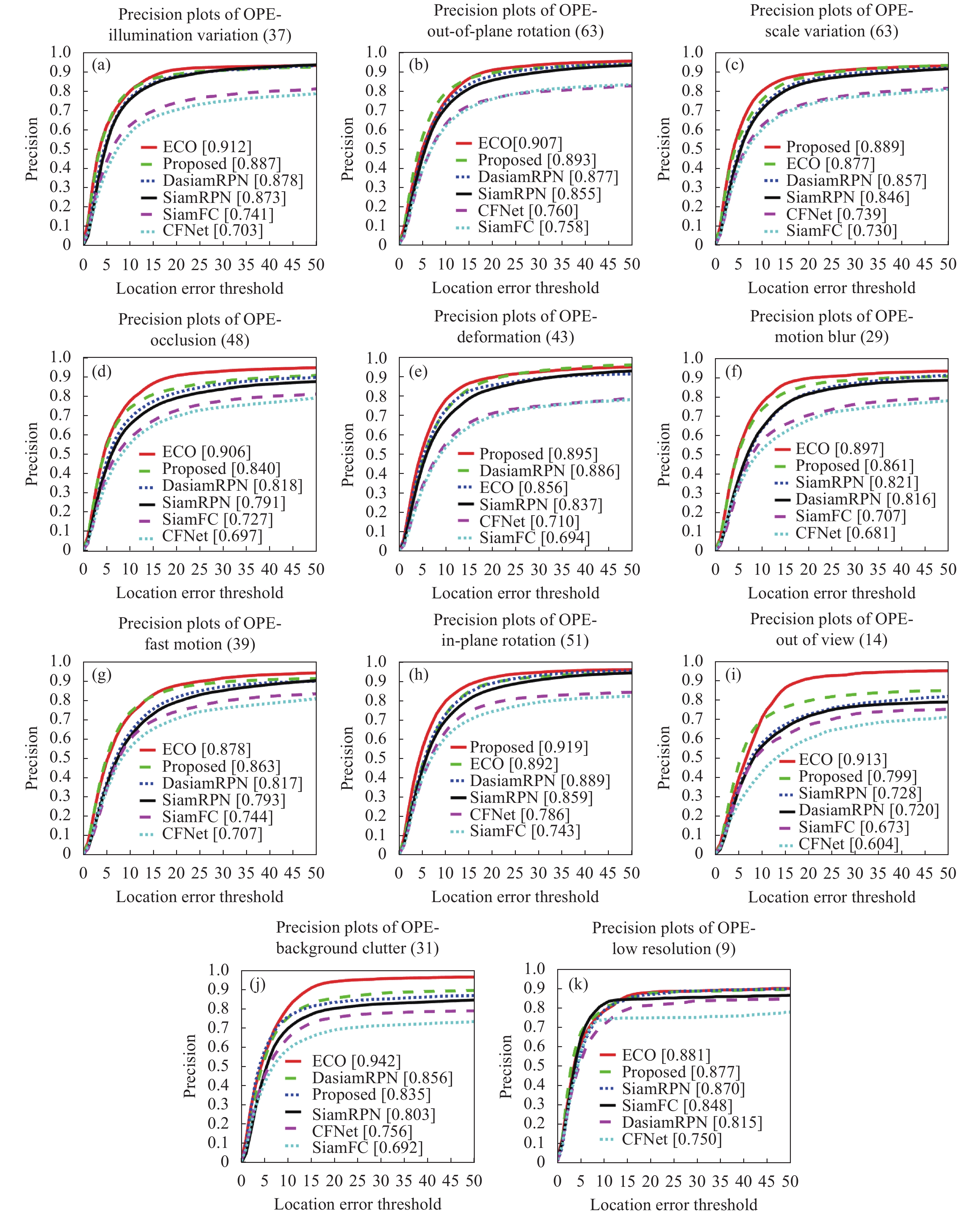
(2)六种算法在OTB-2015中,11种不同属性视频的跟踪精度定量分析结果如图9所示,文中算法在尺度变化、形变、平面内旋转属性中排名第一,在光照变化、平面外旋转、遮挡、运动模糊、快速运动、超出视野、低分辨率属性中排名第二,仅次于ECO。
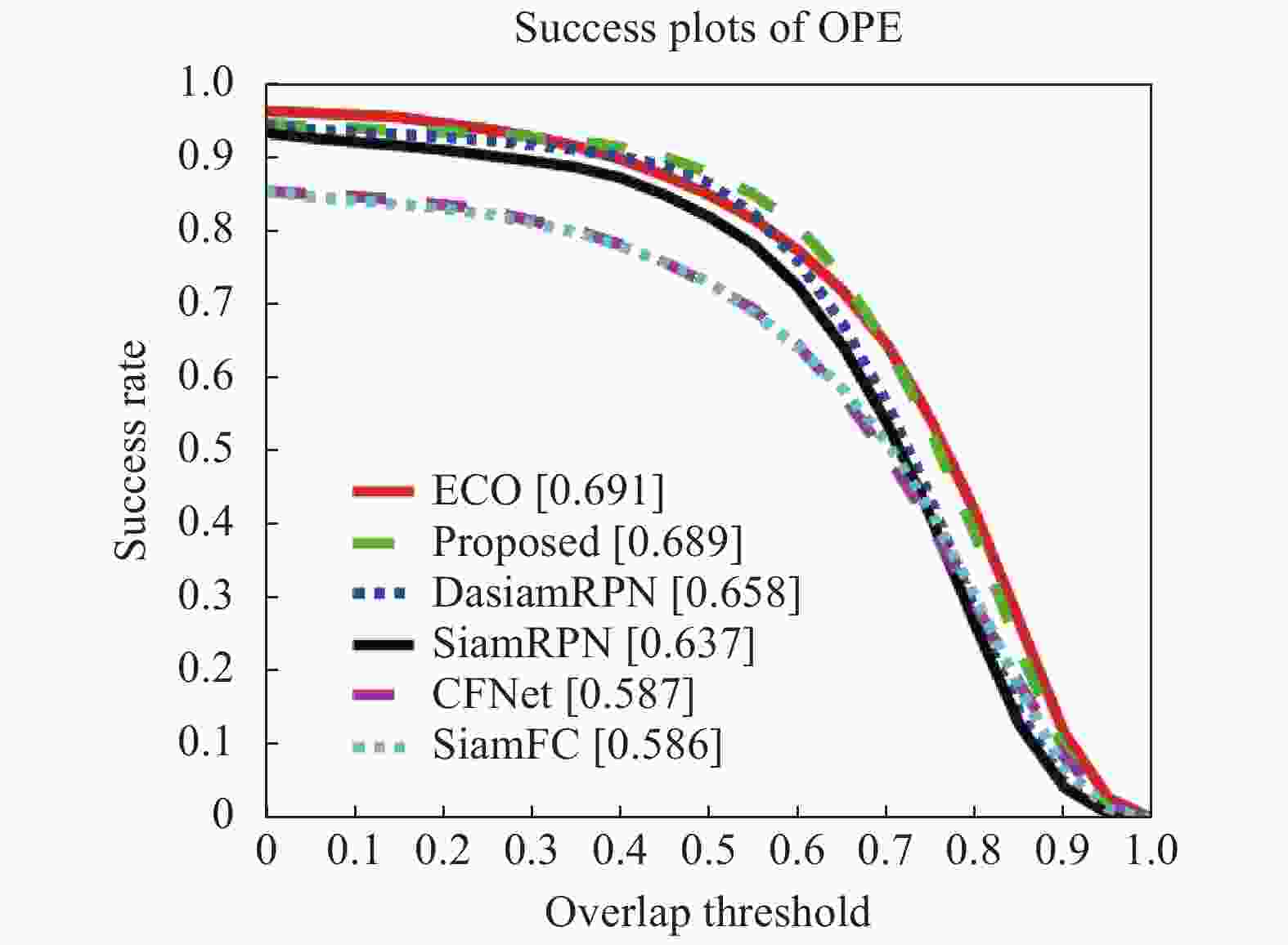
Figure 8. Success plots of OPE on OTB-2015 dataset
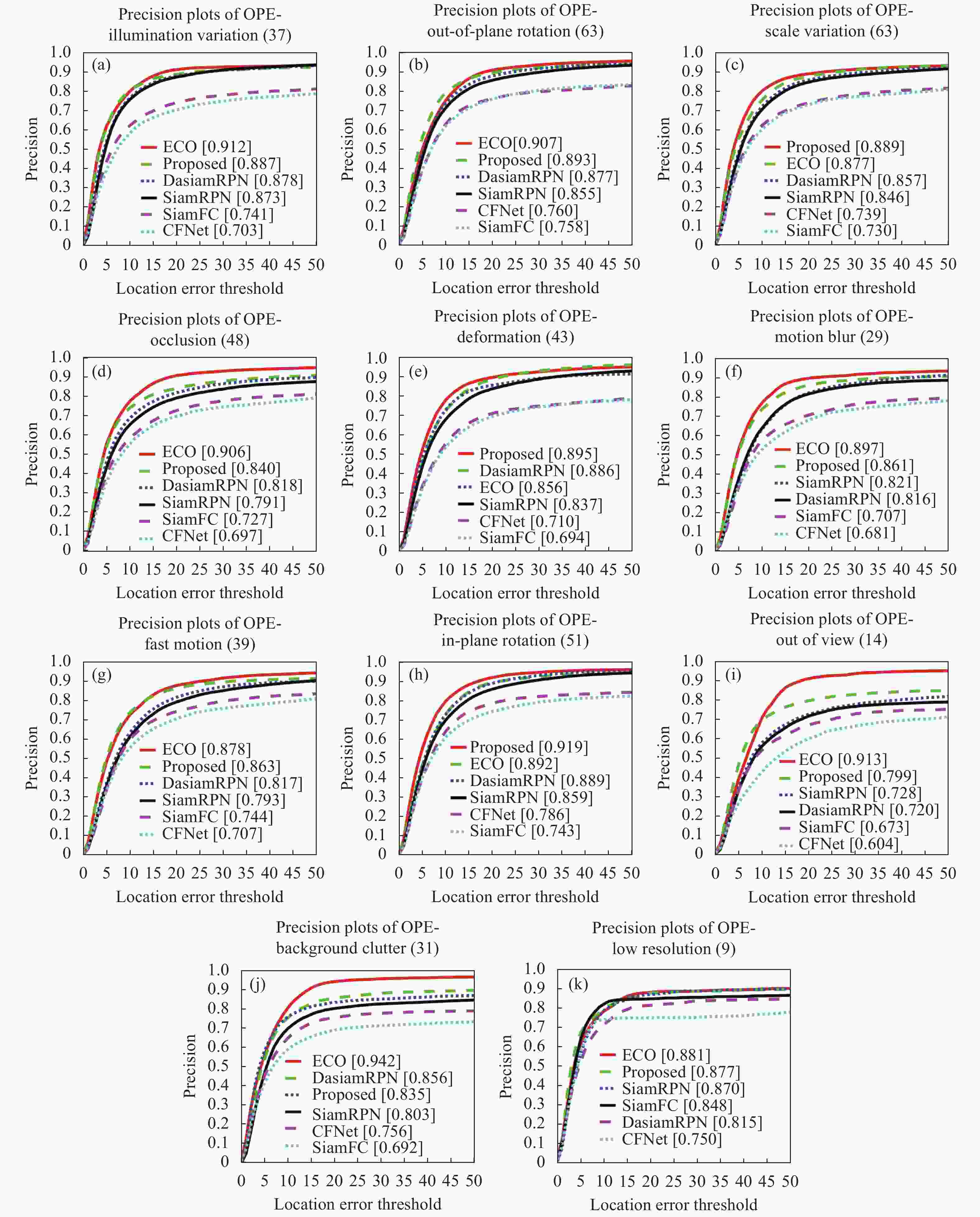
Figure 9. Tracking precision plots of 11 different attributes video sequences on OTB-2015 dataset
(3)六种算法在OTB-2015中不同视频属性的成功率定量分析结果如图10所示,文中算法在尺度变化、形变、平面内旋转、低分辨率属性中排名第一,在光照变化、平面外旋转、遮挡、运动模糊、快速运动、超出视野、背景复杂属性中排名第二,仅次于ECO。
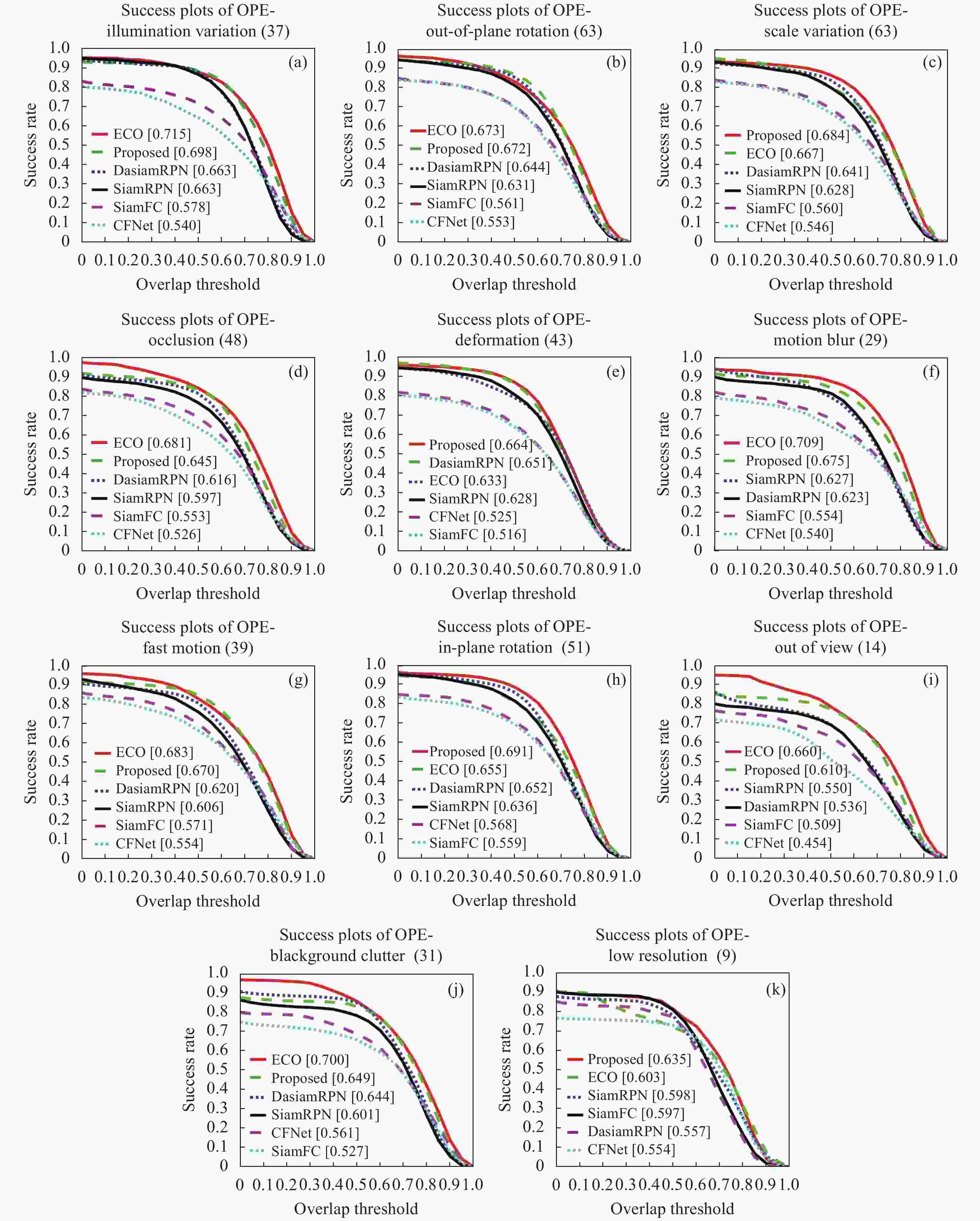
Figure 10. Success plots of 11 different attributes video sequences on OTB-2015 dataset
(4)相较于ECO,文中算法跟踪精度在部分场景仍有差距。然而基于深度网络特征的ECO算法在GPU上的速度为8 FPS[3],文中算法的平均速度达到37 FPS,在跟踪速度上有了提升。
综上,文中所提算法在OTB-2015共11种属性的视频序列中表现稳定,通过融合注意力模块,嵌入更深的网络,取得了很好的跟踪效果,在提高跟踪精度与稳健性的同时,还保证了实时的跟踪速度,较好地适应跟踪场景的变化。
-
文中对基于Siamese网络的目标跟踪算法进行了研究,提出一种嵌入深度卷积网络VGG-Net-16作为特征提取主干网络、融合注意力机制的端到端跟踪算法,并通过实验对其进行了验证,得到以下结论:
(1)通道-互联-空间注意力模块的融入,显著提升了网络模型的特征提取能力、适应能力与判别能力。可视化分析实验表明,注意力模块的存在使得网络覆盖到目标更多的部位,学习更具代表性的特征,同时还可以排除周围相似物的干扰,区分性更强。
(2)在通用目标跟踪数据集OTB-2015上的实验表明,与当前主流算法相比,文中算法能够达到较高的跟踪精度,在目标外观变化、相似物干扰、目标遮挡等复杂场景下,有稳健的表现。
(3)在NVIDIA RTX 2060 GPU下的平均跟踪速度可达到37 FPS,满足实时应用的要求。
注意力机制与目标跟踪算法的融合还处于探索阶段,后续工作会集中于注意力模块在网络中嵌套方式的研究,更进一步提升算法的性能。








































































 DownLoad:
DownLoad: