






-
遥感影像分类是遥感影像处理的研究热点和难点[1]。随着对地观测技术的不断发展,通过不同类型的传感器获取的遥感数据急剧增加。一方面,数据的增加对现有基于小样本的分类方法的效率和精度提出挑战;另一方面,使得利用不同类型、互补性强的观测数据进一步提升分类精度成为可能[2]。
高光谱影像具有光谱分辨率高、数据量大的特点,能精细的反映地物表面的光谱反射特性;LiDAR数据能够获得地物的立体结构信息。许多研究者[3]尝试利用两者的互补性,通过高度信息辅助光谱相似地物的识别,通过光谱信息辅助具有相同高度地物的识别,采用数据融合的方法解决单一数据源进行地物解译面临的挑战。
高光谱和LiDAR数据作为成像机理不同的异构数据,为实现高精度的场景解译,更适合采用特征级和决策级的融合[4]。在特征提取阶段,由于高光谱影像存在数据的冗余,一般首先对其进行降维处理[5-6],再从降维后的光学和LiDAR数据提取特征。然而,由于简单的特征叠加融合可能造成新的信息冗余,容易引发“维数灾难”,也难以反映不同特征对分类的贡献,融合的特征并不总是比使用单一特征源表现得更好。因此,通过特征选择或变换方法对特征集进行再次降维、利用对特征维度不敏感的分类器,都已成为提升分类精度的重要手段。文献[7]将高光谱影像和LiDAR数据提取的光谱、空间和高度特征通过拉普拉斯映射算法实现特征融合。文献[8]利用复核技术分别构造面向空间和光谱类特征的核函数,采用极限学习机实现分类。决策级融合通过将不同分类设置获得的分类结果加以综合实现。典型的决策融合方法有简单多数投票法[9]等。
此外,将初始分类结果与特征学习或区域分割算法结合,以规整对象区域边界,并优化分类的思路,也获得了一定关注[7]。如参考文献[9]利用分割算法获得的区域对象对高光谱和LiDAR分类的结果进行后处理优化,以消除像素分类的“胡椒盐”噪声和规整地物对象边界。
条件随机场(Conditional Random Field, CRF)属于无向概率图模型。基于影像像素类别空间分布的局部平滑假设,CRF可以有效平滑初始分类的噪声,也广泛应用于分类后处理中[9]。其技术关键在于有效保留地物的边界,防止分类结果过度平滑[9]。一般通过在空间能量项中引入边缘、局部光谱差异等度量指标[10-12]加以度量。然而,这类工作仍多针对多光谱或高光谱单一数据源,采用的是底层的统计特征,如何针对多源数据提出局部异质性指标,有效度量类别间的真实差异,仍有待深入研究。
上述研究表明,多源数据分类的精度提升和“胡椒盐”噪声的改善依赖于多阶段、多种处理策略的融合。有鉴于此,受上述多阶段融合思路的启发,同时为了有效表征场景中局部的异质性,保留分类优化结果中的对象边界,文中提出了一种顾及局部特征差异与全局类共生的CRF高光谱-LiDAR融合分类方法。该方法的主要特点是:多源数据提取的光谱-空间-高度融合特征同时用于初始分类和描述地物局部空间异质性,并将全局类共生参数引入目标函数,综合特征融合和优化后处理技术,实现分类精度的提升和“胡椒盐”噪声的消除。
-
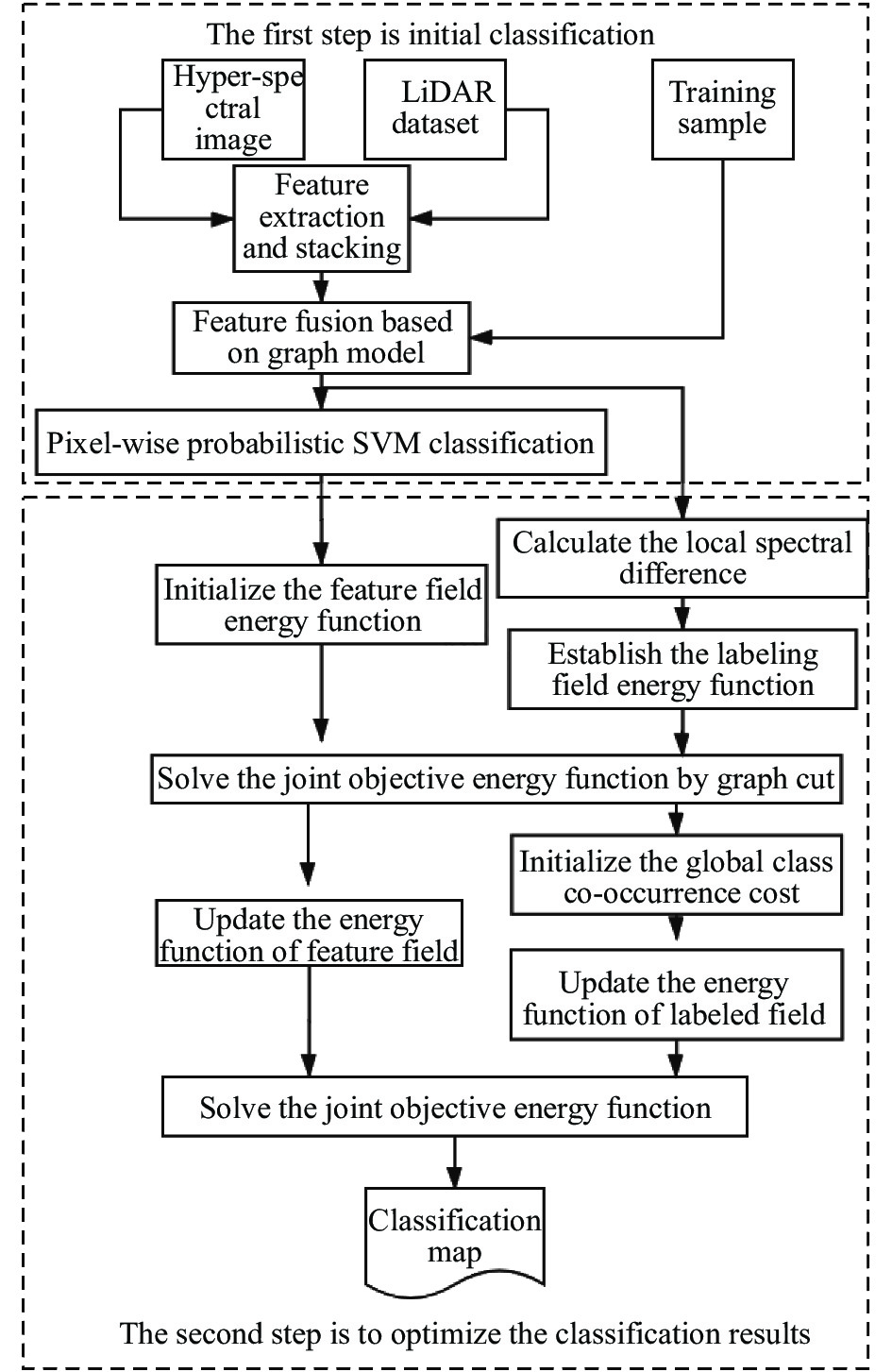
图1为文中提出的CRF分类模型的流程。算法主要包含两个紧密联系的子模块。其一:基于光谱、空间、高度特征融合的初始分类。其目的是为了获得融合特征及初始概率分类结果。首先提取反映场景地物特点的光谱、空间及形态特征,形成高维特征向量,再基于训练样本和广义图模型求解映射函数,将特征映射到低维特征空间,将融合的低维特征输入概率支持向量机获得初始分类结果。其二:分类结果的CRF模型优化。映射获得的低维特征既用于初始分类和初始化特征场能量函数,又用于标记场能量函数中像素间的类别差异的度量。通过迭代求解特征场、标记场联合目标函数获得初次优化结果及目标能量值;更新特征场能量函数,统计类别共生概率,更新标记场能量函数,对新的目标函数求解,获得最终分类结果。

Figure 1. Hyperspectral and LiDAR co-classification by CRF integrating feature dissimilarity and class co-occurrence
-
文中:加粗的斜体大写字母代表集合或矩阵;斜体小写字母代表标量或列向量;字母的斜体下标代表集合或矩阵包含的列向量的索引;字母的正体上标单词缩写为不同类型的特征描述。
给定严格空间配准的高光谱影像和LiDAR生成的DSM栅格数据,即影像像素个数为
$ n={n}_{1}\times {n}_{2} $ ,S表示影像所有$ n $ 个位置的集合,$ {\varOmega }={\left\{{c}_{i}\right\}}_{i=1}^{K} $ 表示类别标签集合,$ K $ 为类别个数。高光谱和LiDAR的融合分类过程,即提取特征$ {{X}=\left\{{x}_{i}\right\}}_{i=1}^{n} $ ,并根据特征$ {x}_{i} $ 赋予$ i $ 像素为类别$ {y}_{i}\in {\varOmega } $ ,并有分类结果$ {{Y}=\left\{{y}_{i}\right\}}_{i=1}^{n} $ 。 -
特征融合分类模块分为基于形态学的多源特征提取、基于图模型的特征融合[10]和基于概率支持向量机的分类三个主要步骤。
一般而言,高光谱影像可以提取光谱和空间特征,LiDAR数据可以提取与高度相关的特征。为不失一般性,将获得的特征记为
$ {\boldsymbol{X}}^{\mathrm{S}\mathrm{p}\mathrm{e}}={\left\{{x}_{i}^{\mathrm{S}\mathrm{p}\mathrm{e}}\right\}}_{i=1}^{n} $ ,$ {\boldsymbol{X}}^{\mathrm{S}\mathrm{p}\mathrm{a}}= $ $ {\left\{{x}_{i}^{\mathrm{S}\mathrm{p}\mathrm{a}}\right\}}_{i=1}^{n} $ 和$ {\boldsymbol{X}}^{\mathrm{D}\mathrm{S}\mathrm{M}}= {\left\{{x}_{i}^{\mathrm{D}\mathrm{S}\mathrm{M}}\right\}}_{i=1}^{n} $ 。其中,$ n $ 为像素个数,$ {x}_{i}^{\mathrm{S}\mathrm{p}\mathrm{e}} $ 、$ {x}_{i}^{\mathrm{S}\mathrm{p}\mathrm{a}} $ 和$ {x}_{i}^{\mathrm{D}\mathrm{S}\mathrm{M}} $ 分别代表第$ i $ 个像素位置提取的光谱、空间和高程相关的三种特征列向量,其维数分别为$ {d}^{\mathrm{S}\mathrm{p}\mathrm{e}} $ 、$ {d}^{\mathrm{S}\mathrm{p}\mathrm{a}} $ 和$ {d}^{\mathrm{D}\mathrm{S}\mathrm{M}} $ 。通过将三种特征进行堆叠,即可获得联合特征矩阵
$ \boldsymbol{X}=\left[{\boldsymbol{X}}^{\mathrm{S}\mathrm{p}\mathrm{e}}{;\boldsymbol{X}}^{\mathrm{S}\mathrm{p}\mathrm{a}};{\boldsymbol{X}}^{\mathrm{D}\mathrm{S}\mathrm{M}}\right]{=\left\{{x}_{i}\right\}}_{i=1}^{n}\in {\mathbb{R}}^{D\times n} $ ,其中,特征总维数$ {D=d}^{\mathrm{S}\mathrm{p}\mathrm{e}}+{d}^{\mathrm{S}\mathrm{p}\mathrm{a}}+{d}^{\mathrm{D}\mathrm{S}\mathrm{M}} $ ,并且$ {x}_{i}=\left[{x}_{i}^{\mathrm{S}\mathrm{p}\mathrm{e}}{;x}_{i}^{\mathrm{S}\mathrm{p}\mathrm{a}}; {x}_{i}^{\mathrm{D}\mathrm{S}\mathrm{M}}\right]{\in \mathbb{R}}^{D\times 1} $ 。特征矩阵
$ \boldsymbol{X} $ 仍具有较高维数,需要进一步约简。流形学习通过求出相应的嵌入映射,可以实现这一目的。拉普拉斯特征映射算法采用一个无向有权图描述一个流形,然后通过图的嵌入求解变换矩阵$ {\boldsymbol{W}}^{\boldsymbol{*}} $ ,即式中:
$ {x}_{i}\in \boldsymbol{X} $ 代表图的节点;$ {\boldsymbol{C}}_{ij} $ 为节点邻接矩阵$ \boldsymbol{C} $ 中$ {x}_{i} $ 与$ {x}_{j} $ 的邻接强度。采用与参考文献[7,10]类似的方式,$ {\boldsymbol{C}}_{ij} $ 也定义为二值矩阵。对$ {x}_{i} $ 中的光谱、空间和高程三种子特征向量分别采用欧式距离寻找与其最接近的$ k $ 个样本,若$ j $ 样本同时出现在三个样本集合中,则$ {\boldsymbol{C}}_{ij}=1 $ ,否则$ {\boldsymbol{C}}_{ij}=0 $ 。拉普拉斯特征映射算法具有计算复杂度低的特点,其详细求解过程可参考文献[10]。利用公式(2)获得融合的特征后,采用概率支持向量机[13]即可获得所有像素的类别标记
${{\boldsymbol{Y}}^{\mathrm{I}\mathrm{n}\mathrm{i}}=}$ ${\left\{{y}_{i}^{\mathrm{I}\mathrm{n}\mathrm{i}}\right\}}_{i=1}^{n}$ 和任意像素$ i $ 属于给定类别$ {y}_{i}\in \mathrm{\varOmega } $ 的概率$ {l}_{i,{y}_{i}} $ 。 -
上述特征融合分类中,分类器独立地预测每个像素的类别,所以无法避免结果中的“胡椒盐”噪声。条件随机场是给定特征变量条件下类别标记变量的马尔科夫随机场。经典条件随机场模型应用于后处理优化[12],通过类别标记变量的局部马氏性约束,可以有效地平滑局部的类别不一致现象,实现分类噪声的滤除。
像素分类结果的优化任务可以描述为:已知观测特征图像
$ \boldsymbol{Z} $ 和初始分类结果$ {\boldsymbol{Y}}^{\mathrm{I}\mathrm{n}\mathrm{i}} $ ,寻找一个地物类别标记随机场$ Y $ 的最大后验估计$ {\boldsymbol{Y}}^{\boldsymbol{*}} $ 的问题,即定义在以像元为节点
$ V $ 、以像元4-或8-邻域为邻接关系的无向图$ G=\left(V,E\right) $ 结构之上,如果给定观测特征$ \boldsymbol{Z} $ 的观测随机场Y的条件概率分布$ P\left(Y|\boldsymbol{Z}\right) $ 为条件随机场,则对于任意一个节点$ i\in V $ ,随机变量$ {y}_{i} $ 应满足:式中:
$ i\ne j $ 表示图$ G $ 中除$ i $ 外的所有节点;$ j\in {N}_{i} $ 表示图$ G $ 中与$ i $ 邻接的节点集合,文中定义为$ i $ 的8邻域位置。同时,根据Hammersley-Clifford定理,$ P\left(Y|\boldsymbol{Z}\right) $ 可以表示为一个Gibbs分布,即式中:
$ {C}_{G} $ 定义为所有一阶和二阶势团的集合;$ {\mathrm{\varnothing }}_{c} $ 为团$ c $ 的对应势函数;规范化因子$ M\left(\boldsymbol{Z}\right) $ 保证$ P\left(Y|\boldsymbol{Z}\right) $ 构成概率分布。将公式(5)代入公式(3),并定义${E}\left(Y|\boldsymbol{Z}\right)= $ $ {\displaystyle\sum }_{c\in {C}_{G}}{\mathrm{\varnothing }}_{c}\left({y}_{c}|\boldsymbol{Z}\right)$ 为Gibbs能量,有:即求解Gibbs能量
$ {\displaystyle\sum }_{c\in {C}_{G}}{\mathrm{\varnothing }}_{c}\left({y}_{c}|\boldsymbol{Z}\right) $ 最小时对应的像素类别标记序列。由于同一特征在所有像素位置都有定义,$ {E}\left(Y|\boldsymbol{Z}\right) $ 又可以重写成一阶势能函数$ {{E}}^{\mathrm{F}\mathrm{e}\mathrm{a}} $ 和二阶势能函数${{E}}^{\mathrm{L}\mathrm{a}\mathrm{b}}$ 的和,即式中:一元势函数
$ {\varphi }_{m}\left({y}_{i},{z}_{i}\right) $ 描述了给定像素位置$ i\in \boldsymbol{S} $ 特征$ {z}_{i} $ 时,$ i $ 属于$ {y}_{i} $ 类别的概率;二元势函数$ {\varphi }_{n}\left({y}_{i},{y}_{j},\boldsymbol{Z}\right) $ 描述了给定特征$ \boldsymbol{Z} $ 时,像素$ i $ 与邻域像素$ j $ 的类别标记关系;超参数$ \;\beta $ 用于调节二阶势能函数的贡献,$ \;\;\beta $ 取值越大,分类图的平滑效果越强。为获得目标函数(公式(6))可求解的数学形式,首先将公式(8)中一元势函数定为:
$ {l}_{i,{y}_{i}} $ 类别概率计算时融合了光谱、空间和高程多种特征,因此相比仅采用光谱特征获得的分类结果将更为精确[12]。在经典CRF模型中,公式(9)中二元势函数
$ {\varphi }_{n}\left({y}_{i},{y}_{j},\boldsymbol{Z}\right) $ 定义为:式中:当
$ {y}_{i}={y}_{j} $ 时,$ \delta \left({y}_{i},{y}_{j}\right)=1 $ ,否则$ \delta \left({y}_{i},{y}_{j}\right)=0 $ 。由于目标函数(公式(6))计算整体能量的极小值,因此二元势函数(公式(11))倾向于为中心像素$ i $ 和邻域像素$ j $ 赋予相同的标识。文中在公式(11)中引入
$ f\left(\Delta _{i,j}\right) $ ,并将二元势函数$ {\varphi }_{n}\left({y}_{i},{y}_{j},\boldsymbol{Z}\right) $ 重新定义为:式中:
$ \Delta _{i,j} $ 度量了中心像素$ i $ 和邻域像素$ j $ 的特征差异性,$ f\left(\Delta _{i,j}\right) $ 为$ \Delta _{i,j} $ 的单调递减函数。公式(12)表明:当局部像素的异质性指标$ \Delta _{i,j} $ 较小时,即相邻的像素具有类似的特征时,像素有更大的可能性属于同类;反之,像素具有较大的可能性不属于同类。文中,$ f\left(\Delta _{i,j}\right) $ 定义为归一化欧式距离$ \Delta _{i,j} $ 的指数函数,即式中:
$ {z}_{i,b} $ 和$ \overline {{z}_{b}} $ 分别代表融合特征矩阵$ \boldsymbol{Z} $ 中$ i $ 位置上第$ b $ 维的特征值及第$ b $ 维特征的平均值。将公式(7)~(14)整合,代入公式(6),有目标函数:相比采用原始数据的像素梯度作为局部异质性度量指标的方法[11],文中采用的特征是空间、光谱和高程特征的融合。由于场景中对象的真正边界往往是多种局部视觉线索的综合,因此融合特征可以更有效地描述不同地物对象的差异。采用欧式距离作为特征差异的度量,主要考虑到采用的基于流形学习的特征融合和降维后,特征空间是一种局部近似为欧式空间的特殊拓扑空间。另外,各特征维逐一归一化的处理方式有效避免了不同特征类型可能存在的量纲不一致的问题。
另一方面,目标函数(公式(15))在二元势函数中仅考虑局部的特征差异性,没有考虑类别间的空间依赖特性,往往会在对象边界上出现细碎颗粒状噪声[12]。因此,在以上获得初次优化结果
$ {\boldsymbol{Y}}^{\mathrm{*}} $ 的基础上,考虑将类别的共生约束引入二元势函数,对初次优化结果进行再次优化,即定义目标函数为:式中:
$d\in \left[\mathrm{1,2},\cdots ,8\right]$ 代表中心像素与8-邻域像素的8种位置关系;$ {y}_{j} $ 为像素位置$ i $ 在d方向上的邻域像素的标记;$ {g}_{d}\left({y}_{i},{y}_{j}\right) $ 为$ {y}_{i} $ 与$ {y}_{j} $ 类别在d方向上的共生概率。公式(16)表明:$ {g}_{d}\left({y}_{i},{y}_{j}\right) $ 为各项异性的函数,不同方向上相同类别对的共生情况也有所不同,目标函数倾向于保留具有更强空间联系的标记对。最后,通过顺序求解目标函数(公式(15)和(16)),顺次对初始结果进行两次优化,即可获得最终的优化分类结果。与参考文献[12]类似,首先采用Graph Cut算法求解目标函数(公式(15)),然后基于优化结果统计初始化类别共生概率的
$ {g}_{d}\left({y}_{i},{y}_{j}\right) $ ,再借助ICM算法迭代优化(公式(16)),获得最终分类结果。 -
为验证所提出的融合分类算法的有效性,采用城区和林区不同场景的数据进行验证实验。
-
该数据集(下文简称Houston数据集)[10],在休斯顿大学校园和邻近城市地区获取,包括1景高光谱影像和1景由LiDAR点云生成的数字表面模型(DSM)栅格数据。其中,高光谱影像的光谱范围为380~1050 nm,包含144个波段,空间大小为349×1 905,空间分辨率为2.5 m,共包含15个地类。图2为高光谱影像(真彩色模式)、DSM,训练和测试样本的数量见表1(a)。在高光谱影像的获取过程中,由于云层的遮挡导致部分研究区域位于阴影之下,在该区域也没有选择训练样本,但部分测试样本位于阴影区域,增大了实验的挑战性。

Figure 2. Houston data set
-
该实验数据集在广西壮族自治区南宁市高峰林场地区获取[14],经过几何校正、拼接、配准等预处理后形成的数据集(下文简称高峰林场数据集)也包括1景高光谱和1景DSM栅格数据。其中,高光谱影像包含125个波段,空间大小为351×2281,空间分辨率为1 m,共15个类别。结合野外调查,获得该场景的训练和测试样本,两者没有交叉。图3为该高光谱影像和DSM,训练和测试样本的数量和图例信息见表1(b)。

Figure 3. Gaofeng forest farm data set
-
拓展形态剖面特征(EMP)通过采用不同形状、依次增大的结构元素对波段进行序列开闭运算,可以有效提取场景中的对象大小和形状空间结构信息,广泛用于空间信息的提取。考虑到研究场景中,道路、房屋、草地、树林、树冠等往往具有规整的边界或规则的形状,基于序列尺寸的圆形和线形结构元素,对DSM和高光谱波段提取多尺度特征,具体参数设置参考文献[7]。
首先,采用序列尺寸的圆形和线形结构元素,分别对DSM波段和高光谱影像提取形态剖面特征,然后,对于共计210维的光谱、空间和高度特征进行基于图模型的特征融合(见1.2节)后,通过不同维数融合特征的精度比较(见3.1节)确定最终保留的特征维数。融合后的特征基于径向基函数,采用概率支持向量机[13]进行分类。其中的模型参数由10-折交叉验证获取。
在分类结果优化阶段,涉及目标函数(公式(15)和(16))中两个超参数
$\;\;\beta $ 的选择问题,默认设置两个超参数取值一致,并通过实验确定较优的参数值。结果评价采用定量精度评价和目视解译结合的方式。分类结果的定量评价采用基于混淆矩阵的整体精度(OA)、Kappa系数以及相关的类别生产者和用户精度等指标。(a) 休斯顿
(a) Houston(b) 高峰林场
(b) Gaofeng forest farmClass name Number of training/testing samples/pixel Sample color Class name Number of training/testing samples/pixel Sample color Healthy grass 198/1053 
Eucalyptus 193/315 
Stressed grass 190/1064 
Road 74/106 
Synthetic grass 192/505 
Tilia tuan 40/52 
Trees 188/1056 
Cultivated land 95/127 
Soil 186/1056 
Acacia crassicarpa benth 208/308 
Water 182/143 
Wasteland 16/20 
Residential 196/1072 
Michelia macclurei dandy 69/95 
Commercial 191/1053 
Building 165/251 
Road 193/1059 
Other broad leaved forests 184/275 
Highway 191/1036 
Pinus massoniana lamb 214/300 
Railway 181/1054 
Cunninghamia lanceolata 34/47 
Parking Lot 1 192/1041 
Water 390/562 
Parking Lot 2 184/285 
Mixed shrub forest 53/84 
Tennis court 181/247 
Bamboo 21/34 
Running track 187/473 
Grassland 23/20 
Table 1. Class names and their numbers
-
基于两个数据集,从特征提取阶段中保留特征维数的影响、超参数
$\;\beta $ 的取值、初始分类方法的影响、与主流方法的对比等方面评估所提出的方法的优劣。 -
首先对图模型融合后Houston 数据集整体精度OA随保留特征维数(1~32)变化的情况进行分析。实验结果表明:随着特征维数的增加,GGF和GGF-CRF的分类精度都在逐渐提升;且对于保留不同维数获得的初始分类结果采用后处理算法后精度均有所提升。高峰林场数据集也有相似的表现。当保留特征维数超过24维后,分类精度开始逐渐下降。保留特征维数在20~32之间时,OA均超过90%;且当融合特征维数取24维时精度最高。因此,后续的保留特征维数均设置为24维。
-
表2为不同
$\;\beta $ 取值下,Houston总体分类精度(OA)、Kappa系数及平均精度(AA)的值。当$\;\beta $ 在一定范围内取值时,3个指标均比较稳定,表现出算法对于$\;\beta $ 取值的鲁棒性。可以认为$\;\beta $ 取值在[0.5, 4.5]范围时,算法对于超参数的取值不敏感。这一结论也被其他研究[9]和文中的高峰林场数据所证实。因此,后续实验中,Houston数据集$\;\beta $ 取值固定为1,高峰林场数据集$\;\beta $ 取值固定为2.5。Precision β 0.5 1 1.5 2 2.5 3 3.5 4 4.5 OA 93.99% 94.00% 93.93% 93.88% 93.89% 93.86% 93.85 93.84% 93.83% Kappa 0.935 0.935 0.934 0.933 0.934 0.933 0.933 0.933 0.933 AA 93.47% 93.42% 93.19% 93.07% 91.30% 93.06% 93.04% 93.04% 93.03% Table 2. Influence of different β values on the final classification accuracy (Houston)
-
为全面评价提出方法的优势和不足,设置不同特征及组合、不同特征融合方法以及不同CRF后处理方法,共7种方法进行对比分析。具体而言:
(1) FSpe:基于光谱特征的SVM分类;
(2) FDSM:基于DSM提取的形态学的SVM分类;
(3) FSpe+FSpa:基于形态学空间特征及光谱主成分结合的分类;
(4) FSpe+FDSM:光谱-高度特征叠加融合分类;
(5) GGF:空间-光谱-高度特征经过图模型融合后进行分类,即文中采用的初始分类方法;
(6) GGF_CRF1:对于GGF的输出结果仅考虑融合特征局部差异性的CRF后处理方法;
(7) GGF-CRF:文中提出的方法。
上述方法中,(1)~(5)属于像素级分类方法(第一组);(6)~(7)属于基于CRF的分类优化方法(第二组)。前者的对比可以评价各类特征的重要性及特征融合方法的有效性;后者的对比可以评价提出优化模型的有效性。
表3(a)展示了两组七种方法在处理Houston数据集的生产者精度对比。整体而言,文中提出的方法(GGF-CRF)在大部分类别上获得了最优或次优的结果,且OA、AA和Kappa均为最高。合成草地、裸土、网球场及跑道的分类精度达到100%,且大部分类别的分类精度均在90%以上。
(a) 休斯顿数据集
(a) Houston data setCategory Pixel level classification method CRF classification optimization method FSpe FDSM FSpe+FSpa FSpe+FDSM GGF GGF_CRF1 GGF-CRF Healthy grass 82.34 24.88 55.69 55.89 81.67 82.43 83.1 Stressed grass 83.36 55.92 84.40 84.49 99.34 99.62 99.81 Synthetic grass 100 91.88 100 100 100 100 100 Trees 93.37 67.23 91.57 98.11 99.24 99.24 99.62 Soil 98.30 76.80 100 99.15 100 100 100 Water 91.61 80.42 99.30 96.50 95.10 95.10 94.41 Residential 76.59 71.74 82.84 91.32 92.35 92.26 93.47 Commercial 56.51 61.92 53.09 52.42 94.59 94.78 95.73 Road 66.57 51.37 79.04 83.95 86.02 85.93 85.74 Highway 72.39 53.86 68.15 79.92 93.24 93.63 94.98 Railway 92.88 83.97 97.34 87.76 90.70 90.80 90.61 Parking Lot 1 78.58 60.71 97.70 79.63 94.24 94.43 97.41 Parking Lot 2 72.98 57.19 81.05 74.04 72.28 71.93 66.67 Tennis Court 98.79 97.17 100 98.79 100 100 100 Running Track 98.31 28.96 98.52 97.67 99.37 99.37 99.79 OA 81.98% 60.48% 85.12% 85.14% 93.34% 93.47% 94.00% AA 84.17% 64.27% 85.91% 85.31% 93.21% 93.30% 93.42% Kappa 0.805 0.597 0.839 0.839 0.928 0.929 0.935 (b)高峰林场数据集
(b) Gaofeng forest farm data setCategory Pixel level classification method CRF classification optimization method FSpe FDSM FSpe+FSpa FSpe+FDSM GGF GGF_CRF1 GGF-CRF Eucalyptus 73.65 60.63 90.79 77.46 86.67 96.82 97.14 Road 48.11 52.83 90.57 66.98 74.53 73.50 73.58 Tilia tuan 5.77 46.15 59.62 53.85 25 32.69 32.69 Cultivated land 83.46 98.43 100 96.85 100 100 100 Acacia crassicarpa benth 71.75 88.31 97.08 87.66 90.91 97.73 97.73 Wasteland 80 55 95 90 95 100 100 Michelia macclurei dandy 31.58 55.79 75.79 70.53 67.37 83.16 84.24 Building 83.27 84.06 96.41 92.83 98.01 97.21 97.21 Other broad leaved forests 70.91 66.55 96.36 65.82 83.27 85.45 85.82 Pinus massoniana lamb 73.67 92.67 92.00 85.67 89.00 96.67 97.00 Cunninghamia lanceolata 12.77 68.09 95.74 65.96 78.72 95.74 95.74 Water 99.82 98.22 100 99.64 100 100 100 Mixed shrub forest 2.38 51.19 73.81 67.86 73.81 88.1 88.1 Bamboo 0 2.94 17.65 17.65 0 0 0 Grassland 10.00 40.00 55.00 85.00 95.00 100 100 OA 71.46% 78.58% 92.41% 83.32% 87.71% 92.37% 92.84% AA 49.81% 64.06% 82.39% 74.92% 77.15% 83.14% 83.28% Kappa 0.674 0.756 0.914 0.811 0.860 0.913 0.919 Table 3. Producer's accuracy comparison of seven classification methods for different data sets
在像素级分类方法中,单一特征的分类结果FSpe和FDSM的整体精度均较低,分别为81.98%和60.48,体现出光谱特征对于遥感分类的基础性作用,也体现出高度特征在区分高度差异不大的地物上的局限性。但阴影区内外地物光谱特征的差异和阴影区训练样本的缺失导致FSpe在阴影区的表现(图4(c))不佳。

Figure 4. Classification results obtained from different feature fusion settings in the shaded area (Houston data set)
光谱-空间联合特征(FSpe+FSpa)和光谱-高度联合特征(FSpe+FDSM)的应用将分类精度分别提升到85.12%和85.14%,表明了光谱与空间、高度特征的互补性。而在FSpe+FSpa简单叠加的特征融合方式建立的特征空间中,阴影区域内外相同地类的样本差异仍然较大,导致该部分分类结果不佳(图4(e))。应用流形学习的广义图融合算法GGF后,由于引入了训练样本在联合特征空间的相似性信息,分类精度进一步提升到了93.34%,表明该算法不仅能降低特征的维数,还能有效去除波段间的冗余,使得样本间的特征差异更适合采用欧式距离度量。如图4(g)所示,阴影区的分类结果明显改善,特别是跨越阴影和非阴影区域的高速公路(高架桥)分类最为完整。
但如图5(a)所示,由于上述5种分类过程均以像素为单位,特征提取即使考虑了局部邻域的信息,分类结果中仍然存在不同程度的“胡椒盐”噪声,地物边界不清晰,仍需要借助后处理手段进行平滑。

Figure 5. Initial classification map and results optimized by different CRF methods (Houston data set)
在GGF方法分类的基础上,两种后处理算法结果各类别和整体精度均略有提高,GGF-CRF的OA、AA和Kappa系数均最高,但数值上GGF-CRF1和GGF-CRF方法精度差异不大。图5为GGF分类及两种优化方法的结果。直观上,图5(b)分类图的视觉差异要远大于精度统计反映的差异,造成这一现象的原因是缺少位于不同对象邻接区域的测试样本。从图5(b)~(c)中还可以看出:两种优化方法在不同程度上减少了GGF中(图5(a))的“胡椒盐”噪声。GGF-CRF1方法考虑了相邻像素间融合特征异质性值,不仅能准确反映不同地物类别之间的边界,并且对于较小的地物类别,在分类结果中也能被保留下来。GGF-CRF在GGF-CRF1的结果上进行再优化,通过考虑类别间的空间共生关系,能有效改善GGF-CRF1方法中的噪声。
根据公式(16),当相邻像素类别相同时,1−
$\delta \left( {{y_i},{y_j}} \right)$ 取0;当相邻像素类别不同时,较强空间关系对应的 1-${g_d}\left( {{y_i},{y_j}} \right)$ 较小。求解公式(16)的极小值,倾向于保留邻域空间关系更稳固的类别对。因此,如表3所示,从GGF-CRF1到GGF-CRF,大多数类别的精度均有所提升,特别是居民区、商业区、高速公路等人工地物类别。 -
表4所示为文中提出的方法与主流融合方法的结果对比。其中,Deep fusion[15]首先使用卷积神经网络方法将光谱数据和激光雷达数据映射为成高度抽象的特征向量,再使用全连接神经网络来融合光谱和激光雷达数据特征,通过网络来训练学习这两种特征的非线性组合。HyMCKs[8]利用复合核来实现异构数据地融合分类。多级融合[4]方法针对特定地物类型的特点设计融合准则,使用投票方法对特征级融合结果进行决策级融合,然后再利用条件随机场对分类结果进行后处理。EC-CRF[11]方法利用Sobel算子分别对高光谱和LiDAR进行边缘提取,并将两种边缘进行组合,根据梯度自适应地控制一个可变加权系数并输入CRF模型中。
Table 4. Comparison of classification accuracy of different methods on Houston data set
从表4中可以看出,文中的方法在总体精度和Kappa值上都处于较高的水平。相比于其他融合算法,该算法能在高光谱和LiDAR数据融合分类上获得较好的效果。
-
表3(b) 展示了上述两组七种方法在高峰林场数据集分类结果的生产者精度对比。整体而言,文中提出的方法(GGF-CRF)在大部分类别上获得了最优或次优的结果,且OA、AA和Kappa均为最高。耕地、荒地、水体及草地的分类精度达到100%,大部分类别的分类精度均在80%以上。同时,目视对比,该数据集的分类结果也具有与图5类似的表现。
因此,与Houston数据集类似的实验结果,实验证实了该算法在提升分类精度和改善“胡椒盐”现象的有效性。
-
在 CPU Intel i7 2.50 GHz、内存64 GB、Windows 7操作系统、Matlab 2019b 环境下测试了算法耗时。在第一特征融合及初始分类步骤中,由于初始分类耗时因特征参数、样本数量和分类器设置而异。统计未包含形态特征提取和SVM交叉验证步骤的时间。
Houston整体处理时间为220.05 s,高峰林场整体处理时间为240.45 s,第二优化步骤比第一特征融合及初始分类步骤需要更多的计算时间。其中,目标函数(公式(15)和(16))的求解占整个处理时间的约70%。第一步处理中,形态特征提取、拉普拉斯特征映射和SVM参数交叉寻优占用超过80%的处理时间。
-
为了充分利用高光谱影像与LiDAR数据的互补性信息,达到提升分类精度和保留地类边界的目的,文中提出了一种特征融合与条件随机场模型耦合的分类方法。该方法对于Houston高光谱-LiDAR实验数据集取得了良好的分类效果。
研究结论主要有以下三点:(1)拓展形态滤波特征对于高分辨率影像中的空间信息具有良好的描述能力,结合流形学习的降维方法能获得较高的分类精度。但因其仍然属于像素级的分类方法,无法从根本上避免分类结果中的细碎噪声。(2)以融合的特征描述条件随机场中二阶势团中的邻域像素的异质性,有效避免了传统随机场模型的标记过度平滑问题;类共生代价函数的引入进一步提升了分类精度。(3)采用融合的特征及概率分类结果初始化条件随机场模型特征场能量,同时将融合特征引入标记场建模,通过特征、决策的协同融合,可以实现地物对象的高精度分类和分类噪声的改善。
下一步工作中,拟将改进该方法在林区场景中树种分类上的应用,以及深度特征与随机场模型的结合。
致 谢 感谢国家重点研发项目“人工林资源监测关键技术研究(2017YFD0600900)”提供文中使用的高峰林场数据集;感谢休斯顿大学高光谱图像分析组和国家航空激光测绘中心(NCALM)提供文中使用的Houston数据集。
Conditional random field classification method based on hyperspectral-LiDAR fusion
doi: 10.3788/IRLA20210112
- Received Date: 2021-02-17
- Rev Recd Date: 2021-06-07
- Publish Date: 2021-12-31
-
Key words:
- hyperspectral /
- LiDAR /
- condition random field /
- feature fusion based on graph model /
- local heterogeneity /
- spatial co-occurrence
Abstract: The interpretation of single remotely sensed data source may suffer from inaccurate boundary and low classification accuracy. The integration of hyperspectral and LiDAR data opens up the possibility to improve the classification performance. But, it is a challenge that how to appropriately integrate the considerable heterogeneity between the two types of data. In this paper, a conditional random field classification method was proposed to solve this problem by jointly taking both the heterogeneity of fused spectral-spatial-height features and co-occurrence of class labels into account. Firstly, the morphological features were extracted from two types of data respectively, and a graph model and training samples were jointly used to fuse the morphological features and spectral features. The obtained features were inputted into a support vector machine classifier to obtain the initial classification results with probabilistic outputs. Then, based on the fusion features, a local heterogeneity value was calculated to measure the essential difference of classes among pixels. Meanwhile, a class co-occurrence matrix, whose element calculated the spatial relationship between classes, was also obtained. Finally, a conditional random field framework was used to integrate the initial classification results, local heterogeneity information and the class co-occurrence matrix, and obtain the final classification results through inferencing two objective functions. In this process, by defining the weight between two neighboring pixel as a monotone decreasing function respect to the normalized Euclidean distance of the corresponding fused features, the object boundary could be regularized by giving a smaller weight to the class pairs with different labels and distinct features. Similarly, by giving a small weight to the class pairs with a strong spatial relationship, the purpose of maintaining the class pairs with stable spatial relations could be achieved. The method was validated with Houston and Gaofeng forest farm data sets. The overall accuracies of the proposed method reached to 94.00% and 92.84% respectively, and the "pepper and salt" phenomena of the initial classification results were significantly reduced. The result indicates the effectiveness of the proposed method.

































































































































 DownLoad:
DownLoad: