






-
随着高光谱技术的不断发展,光谱分辨率与空间分辨率的不断提高,为高光谱矿物识别提供了有效技术手段。传统的矿物识别方法主要基于矿物光谱的相似性或者光谱的诊断特征,较为依赖矿物光谱且容易受成像条件的影响[1-3]。深度学习技术在图像分类和识别领域取得了有效应用,极大地提升了模型的鲁棒性,越来越多的学者将神经网络应用于高光谱矿物识别[4-5]。但是,该类神经网络模型由于网络结构复杂,网络参数庞大,很难满足许多高光谱应用中对矿物的快速信息提取和高效识别的要求。尽管Zhang等[6]将GPU技术应用于矿物识别应用中,提高了计算速度,但是,针对矿物识别模型效率提升的模型结构研究还比较缺乏。Denil[7]等提出神经网络存在着大量的冗余参数,仅需要部分网络参数就能获得与原网络相同的效果。除此之外,Han[8]等提出过多的网络参数会带来过拟合现象,导致识别精度的下降。为了获取高效的矿物识别模型,必须去除神经网络中的冗余单元,因此,对矿物识别模型进行模型压缩成为必要的手段。目前,神经网络模型压缩主要分为网络剪枝、参数量化、设计结构化矩阵、知识蒸馏这四类方法[9]。其中,网络剪枝方法直接作用于神经网络中的冗余单元,在降低模型规模的同时,还能减少过拟合程度,显著提升模型效能,得到了广泛应用[10]。
网络剪枝的核心思想是建立网络元素的重要性判别依据,对重要性低的冗余元素进行剪除,并通过再训练获得新的压缩模型,其主要包括非结构化网络剪枝和结构化网络剪枝[11]。非结构化网络剪枝主要针对神经网络中不同网络层之间的冗余连接进行剪枝,以实现模型压缩[12-14]。但是,该类网络剪枝方法可能会对部分重要连接进行误剪枝,并缺少相应的连接恢复过程,从而导致网络不收敛或者精度严重下降。Guo等[15]提出动态网络外科手术方法,对误剪枝的重要连接进行恢复,在获得高压缩比的同时,几乎没有精度损失。然而,非结构化网络剪枝使得权值参数矩阵呈现稀疏化,不利于硬件的加速,并且需要专门的软件进行支持。结构化剪枝主要针对神经网络中的冗余神经元、卷积核或者通道进行剪枝,以实现网络压缩[16-17]。结构化网络剪枝将网络单元进行整体剪除,不需要特殊的硬件或者软件支持,得到了更为广泛的应用。然而,现有的结构化剪枝方法通常将所有的验证样本作为神经网络单元重要性的数据驱动,并未考虑误识别样本可能造成的影响。
因此,针对上述问题,文中提出了一种基于改进样本驱动的高光谱矿物识别模型压缩方法,对神经网络中冗余神经元进行剪枝,以得到高效的矿物识别模型。该方法以验证数据集中正确识别样本为基础,首先计算各神经元经激活后输出零值频率,即正确识别样本驱动的激活输出零值率(Average Percen tage of Zeros driven by Correctly identified samples, C-APoZ),并将C-APoZ作为神经元重要性依据,然后根据C-APoZ值对神经网络进行迭代剪枝,实现对原网络的高效压缩。为验证方法的有效性,将提出的模型压缩方法应用于基于多层感知机的矿物识别模型,并以美国内华达州Cuprite矿区的AVIRIS高光谱数据作为测试数据。
-
目前,深度学习神经网络模型已经在高光谱矿物识别方面得到了应用[5],文中提出的基于改进样本驱动的高光谱矿物识别模型压缩方法将这些模型视作预训练模型,在此基础上进行网络剪枝。该方法利用神经元的
${C\text{-}APoZ}$ 作为重要性判断依据,对预训练神经网络逐层进行剪枝,并对剪枝网络进行再训练,通过多次迭代实现对高光谱矿物识别模型的高效压缩。 -
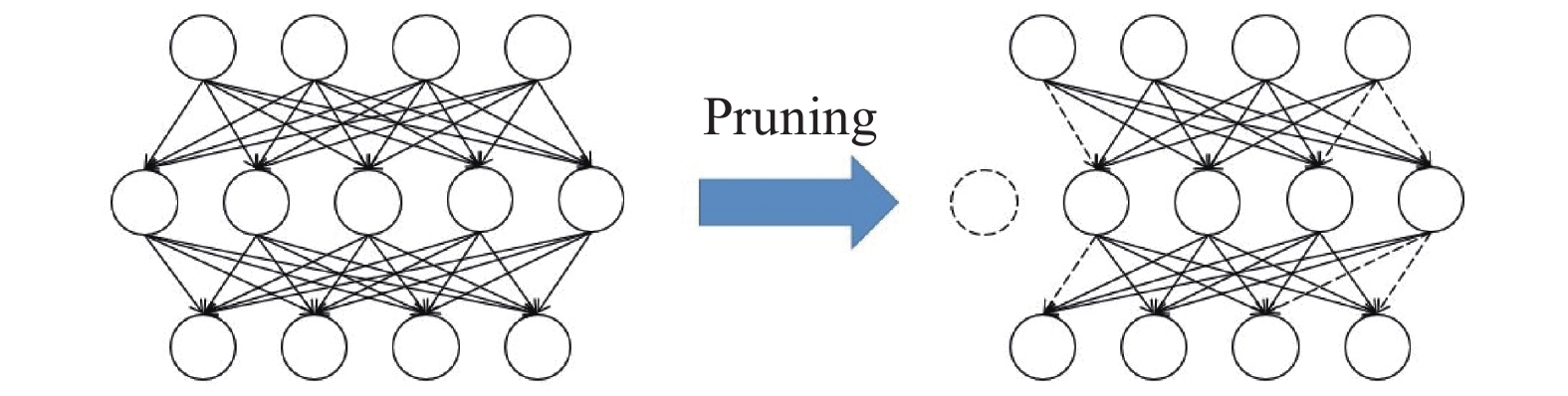
基于神经网络的高光谱矿物识别模型,由于网络层数多,每层的神经元数目多,使得不同网络层之间的连接较多,导致整个矿物识别模型复杂,计算时间长。网络剪枝方法可以剪除神经网络中的冗余单元,实现对模型的压缩,其示意图如图1所示。虚线部分为网络剪枝方法去除的冗余元素。

Figure 1. Schematic of network pruning
神经网络大部分的参数存在于全连接层中,故针对全连接层的网络剪枝成为重要的研究方向[7]。若依据连接重要性进行非结构化剪枝,会造成权值矩阵稀疏化,需要专门的硬件和软件支持,故将其转化为对神经元的结构化剪枝。为了探究全连接神经网络中各神经元的重要性,研究相邻三层网络层组成的局部神经网络,分别记作L−1层、L层和L+1层。为了方便数据在神经网络中的表示,令
${{X}}_{i}$ 为第i层网络层的输出,${{W}}_{i}$ 和${{b}}_i$ 分别为连接第i−1层网络层和第i层网络层的权重矩阵和偏置向量。局部神经网络的各网络层输出之间的关系如下式所示:式中:
$ \sigma (\cdot)$ 为神经网络的激活函数。为了克服网络的梯度消失问题,并且加速网络的收敛速度,通常选择ReLU函数作为全连接层的激活函数,其计算公式为:由公式(1)~(3)可得出,若
${{X}}_{L}$ 中第j个神经元的输出$X_L^j$ 为0时,则与其相连的权重在该次计算过程中不再发生任何作用,且对最后的识别结果不产生任何影响,可视其为冗余神经元。通常采用验证样本集在神经网络模型上的表现来衡量该模型的效能,因此,可利用验证样本集作为数据驱动来探讨神经网络各神经元的冗余程度。当以整个验证样本集作为数据驱动时,若某一神经元的输出零值次数越多,则其对神经网络输出结果的影响越小,其重要性越低,越有可能成为冗余单元。Hu等[17]提出以激活输出零值率(Average Percentage of Zeros, APoZ)作为神经元重要性判断依据,采用基于样本驱动的剪枝方法对神经网络进行剪枝,获得了较为高效的压缩模型。神经元的APoZ值越大,其重要性越低,被剪枝的优先级越高。第L层网络层的第i个神经元的$APoZ_L^i$ 的计算公式为:式中:N为验证样本的数量;
$X_L^i(k)$ 为第k个验证样本在第L层网络层的第i个神经元的激活输出,若$X_L^i(k)$ =0,则$ f(·)$ 的值为1,否则,$ f(·)$ 的值为0。基于样本驱动的网络剪枝方法以整个验证样本集作为数据驱动,逐网络层对APoZ值高的神经元进行剪枝,实现网络压缩。由于被剪枝的神经元输出零值频率高,对神经网络的输出结果产生影响小,故剪枝后的网络与剪枝前的网络在验证样本集上具有相似的输出。因此,剪枝网络不仅保留了原网络对大部分样本正确识别的能力,还保留了对部分样本错误识别的能力,这可能导致识别精度下降。
针对这一问题,文中提出基于改进样本驱动的剪枝方法,以验证样本集中的正确识别样本作为数据驱动来判断神经元的重要性,即利用C-APoZ作为神经元重要性判据。第L层网络层的第i个神经元的
$C{\text{-}}APoZ_L^i$ 的计算公式为:式中:当第k个样本为正确识别样本时,
$Fla{g_k}$ 为1,否则,$Fla{g_k}$ 为0。对于一个能识别K类矿物的神经网络矿物识别模型,当以验证样本作为数据驱动时,若识别正确,则识别模型的输出类别标签唯一;若识别错误,则输出类别标签可能存在K−1种可能,故错误识别样本对于模型具有不可预测性,很难评价其对于模型神经元的影响。利用文中提出的C-APoZ来衡量神经网络中各神经元的重要性时,对验证样本进行筛选,仅以正确识别验证样本作为驱动,忽略了错误识别样本可能带来的随机影响,最大程度保留了原模型对验证样本集正确识别的能力,是剪枝网络模型效能提升的重要保障。除此之外,基于C-APoZ神经元判据相较于传统的基于APoZ神经元判据,去除了错误识别样本对于剪枝网络的限制,降低了模型过拟合程度,有助于提升剪枝网络的识别精度。
-
考虑到连接仅存在全连接神经网络的相邻网络层之间,且前网络层的输出才会对后网络层的输出产生影响,故必须逐网络层进行网络剪枝。为了确定神经元是否被剪枝,需要逐网络层设置合适的C-APoZ阈值,对冗余神经元进行剪枝,降低网络的冗余性。文中选取第L层网络层C-APoZ值的平均值与标准差之和作为该层神经元重要性阈值TL,对于该层的第i个神经元,若
$C{\text{-}}AP{\rm{o}}Z_L^i > {T_L}$ ,则此神经元被剪除;否则,将其进行保留。在对神经网络进行剪枝后,剪枝网络的识别能力会呈现一定程度的下降,需要对其进行再训练,对模型参数进行微调,以获得稳定的压缩网络。另外,单次的网络剪枝很难获得高压缩比的压缩网络,需要进行多次迭代剪枝,才能获得高效的压缩矿物识别模型。 -
全连接层能够对浅层特征进行特征重组,获得更为丰富的深层次特征,同时也能提升神经网络模型对特征的非线性表达程度,被广泛应用于高光谱矿物特征提取。但是,全连接层也带来了大量的参数,增加了模型的冗余程度和过拟合程度,成为高光谱矿物识别模型效能提升需要重点关注的对象。文中提出基于改进样本驱动的神经元重要性判据C-APoZ,定量化描述全连接层中各神经元的冗余程度,并通过设置合适的阈值对冗余神经元进行剪枝,多次迭代后获得高压缩比和高识别精度的压缩矿物识别模型,其流程图如图2所示。其中,Epoch为设置的迭代总次数,Iteration为当前迭代次数。
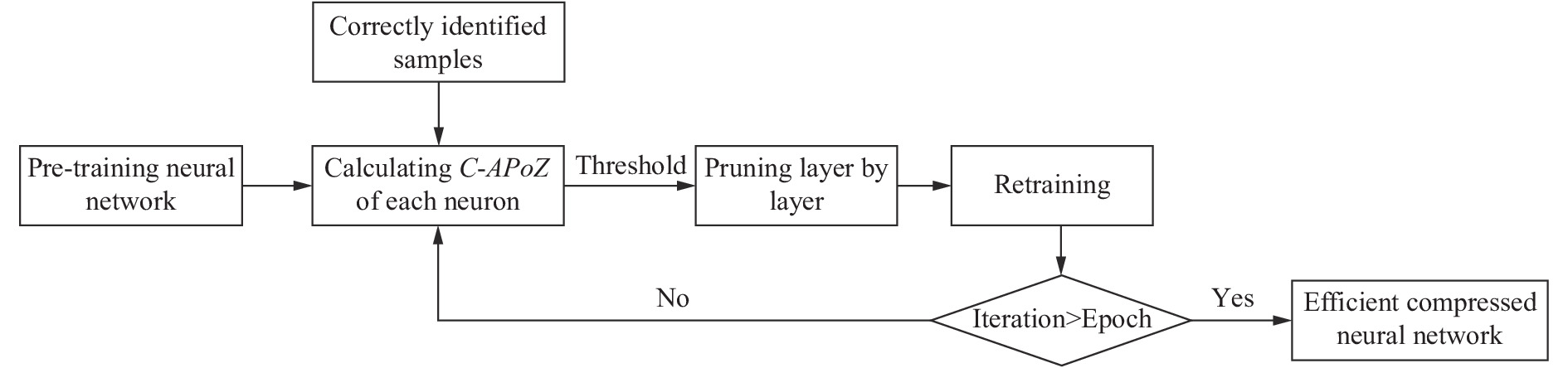
Figure 2. Flow chart of improved sample-driven compression method for hyperspectral mineral identification model
文中提出的基于改进样本驱动的高光谱矿物识别模型压缩方法具体实现步骤如下:
(1)加载预训练高光谱矿物识别模型;
(2)计算全连接网络层各神经元的重要性判据C-APoZ,并计算各层的C-APoZ阈值;
(3)逐网络层对C-APoZ高于阈值的冗余神经元进行剪枝;
(4)对剪枝网络进行再训练,使其达到稳定状态;
(5)重复步骤(2)~步骤(5),直至达到迭代次数;
(6)获得高效能的压缩矿物识别模型。
-
在验证过程中,选取基于改进光谱吸收指数向量的多层感知机矿物识别模型[5]作为预训练神经网络模型。该模型以多层感知机为基础,包含输入层、隐藏层和输出层,各网络层之间为全连接层。其中,输入层为改进光谱吸收指数向量;隐藏层为一层包含多个隐藏单元的网络层;输出层为矿物类别标签。该实验主要将基于改进样本驱动的网络剪枝方法应用于预训练神经网络以获得压缩矿物识别模型,并且探讨压缩程度和识别精度变化。
-
该实验选取AVIRIS传感器采集的美国内华达州Cuprite矿区的高光谱数据作为测试数据。该数据的大小为400×350 pixel,包含50个波段,光谱范围为1 990~2 480 nm。Clark等[18]利用Teracorder系统对该区域AVIRIS数据进行矿物填图,获得了相应的地面真值图。内华达州Cuprite矿区的假彩色图和地面真值图如图3所示。

Figure 3. Hyperspectral datasets of the Cuprite mine in Nevada
实验选取内华达州Cuprite矿区7类分布广泛的矿物进行识别,它们分别是白云母、高岭石、多水高岭石、方解石、蒙脱石、明矾石和玉髓石。各类矿物随机选取100个样本作为训练样本,白云母、高岭石、多水高岭石、蒙脱石4类矿物随机选取400个样本作为验证样本,而多水高岭石、方解石、玉髓石3类矿物随机选取240个样本作为验证样本。7类待识别矿物的信息如表1所示。
Class name Training
samplesTesting
samplesDiagnostic
bands/nmMuscovite 100 400 2 200, 2 350 Halloysite 100 240 2 170, 2 210 Calcite 100 240 2 160, 2 340 Kaolinite 100 400 2 170, 2 210 Montmorillonite 100 400 2 230 Alunite 100 400 2 170, 2 320 Chalcedony 100 240 2 250 Total 700 2320 Table 1. Information of identified minerals
-
该实验选取基于改进光谱吸收指数向量的多层感知机矿物识别模型作为预训练神经网络模型[5]。该网络模型最重要的参数为隐藏层神经元个数h, 为了方便后续剪枝操作,需选取合适的h使预训练神经网络模型的识别精度达到局部极值点。选取不同的h,预训练神经网络模型的识别精度如表2所示。
h Overall accuracy 10 91.98% 15 92.54% 20 93.01% 25 93.36% 30 93.62% 35 93.14% 40 92.76% 45 92.50% Table 2. Model identification accuracy corresponding to the different number of hidden units
由表2可知,当隐藏层神经元数目h为30时,预训练神经网络模型的识别精度达到极大值93.62%,将此时的模型状态作为剪枝的初始状态。
-
预训练神经网络包含三层网络层,其中,输入层与输出层不能进行网络剪枝,故仅针对隐藏层进行网络剪枝。选取验证样本集中的2320×93.62%≈2172个正确识别样本作为文中提出的基于改进样本驱动的剪枝方法的数据驱动,计算隐藏层30个神经元的C-APoZ值。为了与传统的基于样本驱动的网络剪枝方法进行比较,以整个验证样本集作为数据驱动,计算隐藏层各单元的APoZ值。除此之外,分别计算隐藏层的C-APoZ阈值和APoZ阈值,结果如图4所示。

Figure 4. Importance diagram of neurons in hidden layer
由图4可知,由于正确识别样本占据了验证样本中的绝大部分,使得隐藏层各单元的
${{C\text{-}APoZ}}$ 值和APoZ值变化不大。但是,它们的重要性阈值发生了变化,从而使得剪枝结果发生变化。分别以${{C\text{-}APoZ}}$ 和APoZ作为神经元重要性判据对预训练网络进行网络剪枝,并对剪枝网络进行再训练,以压缩比和识别精度对压缩网络进行评价,结果如表3所示。其中,压缩比为神经网络压缩前后所占存储空间的比值。Importance criteria Sequence number of the pruned neuron Number of pruned units Compression rate Identification accuracy after retraining Proposed C-APoZ 1, 4, 6, 12, 17, 20, 23, 27 8 1.36 94.61% APoZ 1, 4, 6, 12, 17, 20, 23 7 1.30 94.57% Table 3. Result chart of different pruning methods
从表3可以看出,以文中提出的C-APoZ作为神经元重要性判据进行剪枝时,能够获得压缩比和识别精度更高的压缩网络。为了验证被剪枝神经元的冗余性,图5给出了Cuprite矿区在被剪枝神经元的输出图像。

Figure 5. Output results of the pruned neurons
由图5可以直观发现,被剪枝的神经元部分所含信息较少,部分具有相似的输出,故可认为它们均为冗余单元。如第1、12、17神经元对于任何输入数据,其输出均为零值,其对网络几乎不产生影响;第6、23、27神经元具有较为相似的输出,其对网络有着相似的影响。分别以
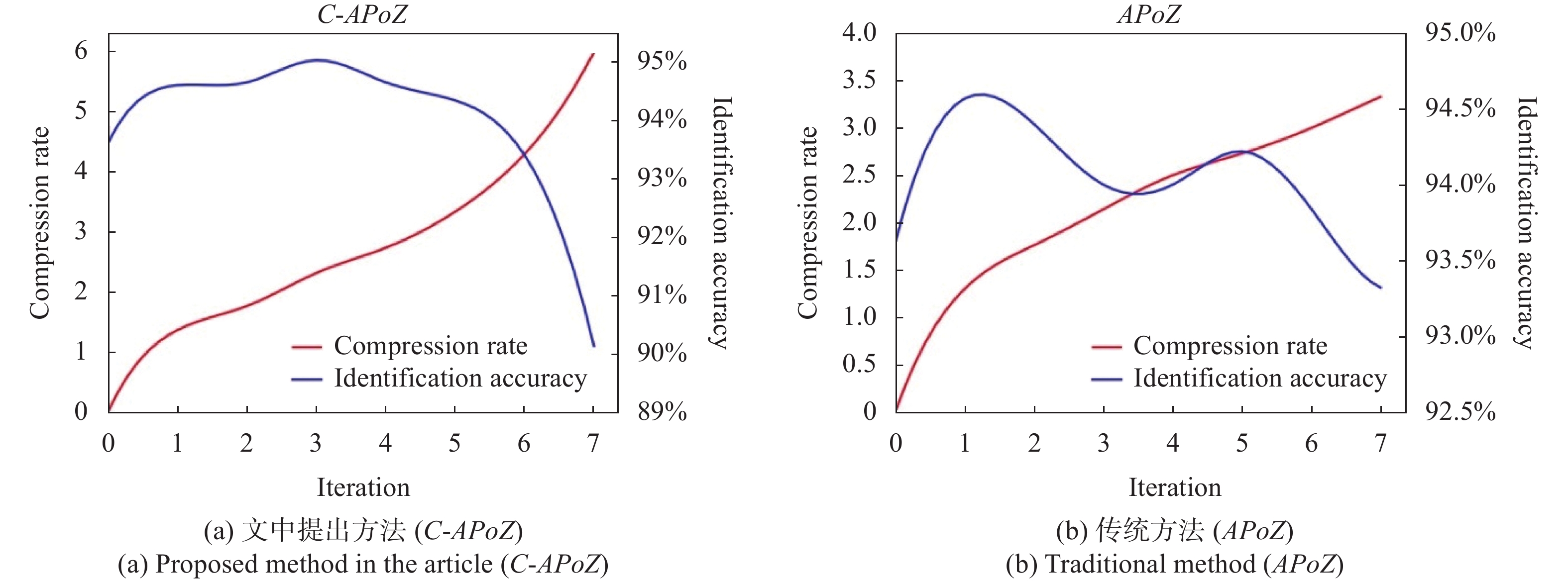
${{C \text{-} APoZ}}$ 和APoZ作为神经元重要性判据进行多次迭代网络剪枝,表4中给出了7次迭代剪枝的结果。Iteration C-APoZ (Proposed method) APoZ Compression rate Threshold Identification accuracy Compression rate Threshold Identification accuracy 0 0 0.817 93.62% 0 0.814 93.62% 1 1.36 0.651 94.61% 1.30 0.643 94.57% 2 1.76 0.502 94.66% 1.76 0.597 94.40% 3 2.31 0.464 95.04% 2.14 0.469 94.00% 4 2.73 0.445 94.66% 2.50 0.426 94.00% 5 3.33 0.448 94.35% 2.73 0.444 94.22% 6 4.29 0.379 93.41% 3.00 0.435 93.84% 7 6.00 0.316 90.13% 3.33 0.412 93.32% Table 4. Iterative pruning results based on different importance criteria
在选取高效能的压缩矿物识别模型时,需要综合考虑其压缩比和识别精度,保证矿物识别模型总体识别精度的基础上,尽可能地提升模型的压缩比,去除模型中的冗余单元。图6给出了基于不同重要性依据的网络剪枝方法在迭代过程中获得的压缩识别模型对应的模型参数。

Figure 6. Parameters of the compressed identification models obtained in the iterative pruning process
为了分析文中提出的剪枝方法对识别效果的影响,图7给出了原始神经网络模型和迭代剪枝5次获得的压缩模型在实验数据区域的矿物识别结果图。

Figure 7. Identification results of the Nevada mining area
-
文中利用基于改进样本驱动的网络剪枝方法对基于改进光谱吸收指数向量的多层感知机矿物识别模型进行网络剪枝,并且与传统的基于样本驱动的网络剪枝方法进行比较,剪枝结果如表4所示。两种剪枝方法获得的压缩模型在识别精度方面均得到一定程度的提高,说明预训练神经网络模型存在着过拟合现象,对其进行网络剪枝是十分必要的。随着迭代剪枝的进行,压缩模型的重要性阈值不断下降,说明神经元C-APoZ值整体下降,神经网络模型的冗余性也随之下降。在相同压缩比的情况下,如压缩比为1.76、2.73和3.33时,尽管识别模型结构一样,但是压缩模型的形成过程不同,使得模型处于不同的稳定状态,参数达到了不同的局部最优值,而基于改进样本驱动的网络剪枝方法总能够获得识别精度更高的压缩模型,充分说明文中提出的剪枝方法能够尽可能保留原模型正确识别样本的能力。如图6所示,在5次迭代剪枝之前,压缩模型识别精度变化不大,压缩比进一步提升,模型效能不断提升;在迭代过程超过5次以后,图6(a)中压缩模型的压缩比尽管显著提升,其识别精度也随之明显下降,而图6(b)中压缩模型的压缩比提升缓慢,其识别精度也显著下降。因此,文中认为经过5次迭代剪枝后,两类剪枝方法所获得的压缩模型效能达到最高。此时,基于改进样本驱动的网络剪枝方法获得压缩比和识别精度分别为3.33和94.35%的高效压缩识别模型,在两种评价指标上均优于传统的基于样本驱动的网络剪枝方法所获得的压缩模型,体现了文中提出方法在高光谱矿物识别模型压缩方面的优越性。另外,图7中,基于改进样本驱动的网络剪枝方法尽管去掉了大量的神经元,大大压缩了模型规模,但是仍然能获得与原模型相似的识别结果图,同样展示了文中提出方法在模型压缩方面的高效性。
-
文中提出基于改进样本驱动的网络剪枝方法,针对高光谱矿物识别模型中存在的冗余神经元进行剪枝,在降低神经网络冗余性和过拟合的同时,提升了矿物识别精度,获得了高效的压缩矿物识别模型。该方法相相较于传统的基于样本驱动的网络剪枝方法,摒弃了误识别样本对神经元重要性的影响,只对原模型正确识别样本的能力进行保留。实验结果表明,利用文中提出的剪枝方法对已有高光谱矿物识别模型进行网络剪枝,获得了压缩比为3.33的高效压缩识别模型,对Cuprite矿区高光谱数据的识别精度也由93.62%提升到了94.35%,充分体现了该剪枝方法的高效性。后续需要对误识别样本对神经元重要性带来的负面影响进行分析,以获得更加全面的神经元重要性判据。
Improved data-driven compressing method for hyperspectral mineral identification models
doi: 10.3788/IRLA20210252
- Received Date: 2021-12-10
- Rev Recd Date: 2022-01-25
- Publish Date: 2022-04-07
Fund Project:
National Key Research and Development Program of China(2016YFB0500505,2017YFC0602104); National Natural Science Foundation of China (61975004);Demonstration System for Remote Sensing Application of High Resolution Land Resources (Phase II)(04-Y30B01-9001-18/20);Qingdao Entrepreneurial Innovation Leading Talent Program (18-1-2-22-zhc)
-
Key words:
- neural network /
- network pruning /
- hyperspectral /
- mineral identification
Abstract: It was difficult to extract mineral features efficiently and quickly from large quantities of hyperspectral data obtained by airborne imaging hyperspectral spectrometers. An improved data-driven compressing method for mineral identification models was proposed in this paper, which pruned redundant neurons in neural networks to obtain efficient mineral identification models. Firstly, the average percentage of zeros driven by correctly identified samples in the validation set (C-APoZ) of each neuron was calculated as a criterion of importance for the neuron, so as to explore the contribution of the neuron to the network for identifying samples correctly. Then, the redundant neurons were pruned by setting the importance threshold, and the pruned network was retrained to improve the identification accuracy while preserving the correct identification abilities of the original network. Finally, an efficient compressed model for mineral identification was obtained through multiple iterative pruning. In this paper, the improved data-driven compressing method was conducted on the mineral identification models based on multilayer perceptron (MLP) to promote their efficiency. The hyperspectral data of the Nevada mining area collected by Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) were applied to evaluate the proposed method. The results show that the proposed method obtained an efficient model for mineral identification with the compression rate of 3.33 and the identification accuracy of 94.35%.
























 DownLoad:
DownLoad: