







-
激活函数(Activation Functions,AF)的主要作用是将非线性因素引入卷积神经网络(Convolutional Neural Network,CNN),为整个模型提供充足的非线性扭曲力,进而帮助CNN更好的理解和拟合复杂函数模型,完成各项计算机视觉任务。
CNN早期发展阶段常用的激活函数有Sigmoid[1]、Tanh[2]函数,二者均属于S型饱和函数,这种函数容易导致梯度消失,使得模型训练困难。为了解决这一问题,Krizhevsky[3]提出了一种线性整流单元(Rectified Linear Units,ReLU)并在当年的ImageNet ILSVRC比赛中取得了出色的成绩,相较于Sigmoid和Tanh函数,ReLU函数具有良好的稀疏性和较小的计算量,它不仅解决了梯度消失问题,还加快了网络训练速度,因此ReLU函数很快便成为CNN网络中常用的主流激活函数,但ReLU函数同样存在着一些缺陷,即ReLU函数容易在训练过程中导致神经元“坏死”[3],进而使“坏死”的神经元在整个训练过程中失去传递信息的能力,对模型产生不利的影响。
为了解决上述问题,基于ReLu函数的改进型激活函数出现了。如Dubey A K[4]等提出的LeakyReLU激活函数在函数负半段设计了泄露单元,有效缓解了神经元“坏死”问题;He K[5]等人提出的非线性修正激活函数PReLU通过引入额外的可学习参数不仅很好的解决了“坏死”问题,还有效提高了模型的拟合能力;Clevert D A[6]等提出的ELU激活函数同样取得了比ReLU函数更优越的性能;上述改进型函数均主要针对ReLU负半轴的零常函数做出改动,进而有效的弥补了ReLU函数的缺陷,但它们同样存在新的问题,如延长了训练时间、提高了训练难度等。
随后,人们想到通过合并多个函数优点的思路来构建新的激活函数。如石琪[7]等提出的组合激活函数ReLU-Softplus,王红霞[8]等提出的ReLU-Softsign激活函数均获得了比单一激活函数更好的效果,组合函数采取优势互补的思路实现了更好的性能提升,但在实际应用中,组合函数同样存在一些新的问题,如ReLU-Softplus对学习率的设置要求严格,ReLU-Softsign在速度和精度方面仍有待提升。
综上,ReLU函数具有良好的稀疏性和运算效率,但本身存在神经元“坏死”问题;LeakyReLU等改进函数通过在负半轴引入非零函数改善了ReLU的缺陷,却给自身带来效率慢的问题;组合函数虽然把不同激活函数优点合并在一起,但又产生了训练困难的新问题。因此,对当前CNN网络来说设计一个既能解决以往激活函数存在的梯度弥散、神经元“坏死”等缺陷,又能加速训练、提升性能且不增加训练难度的高效激活函数是非常必要的。
-
卷积神经网络(CNN)引入激活函数的主要目的是给模型引入非线性因素,从而使CNN模型能实现更好的学习效果,那么激活函数是怎样对CNN模型产生作用的呢?下面通过推导激活函数在网络训练过程中的具体计算过程分析说明。
CNN训练通常包括前向和反向传播两个过程[8],前向传播是指输入信号通过一个或多个网络层进行传递,最后在输出层得到实际输出的过程;反向传播则是模型根据实际输出和期望输出计算出误差损失,然后通过每层的误差损失推导参数的学习规则,选择更优的参数使实际输出更接近期望值的过程。假设有一个l层的网络,给定一个输入
${x_i}$ ,前向传播时上一层的输出经过第l层卷积过程如下:式中:i表示第l-1层的第i个通道;j表示第l层的第j个通道;M表示一个内含j个元素的集合;
$x_i^{l - 1}$ 为第l-1层的输入;$k_{ij}^l$ 为第l层的卷积核,$b_i^l$ 为第l层的偏置项;$ y_j^l $ 为上层输入经过第l层卷积计算的输出。随后把$ y_j^l $ 代入任意激活函数f中去,计算如下:其中,
$x_j^l$ 是一个完整前向传播的输出结果,这里f的主要作用是将非线性因素引入到网络中去,使得CNN中上下层卷积层不再成线性关系,进而促进网络更好的学习和拟合函数模型[9],由于每层网络后都有激活函数参与计算,所以激活函数计算是否简便,求导是否方便将对模型的训练速度产生极大的影响[10]。而反向传播实际上是一个负反馈过程,f在反向传播过程中参与的计算为:
(1)计算第l层的灵敏度
式中:
$\lambda _j^l$ 为第l层的灵敏度;E为误差损失;$\;\beta _j^{l + 1}$ 为第l+1层里下采样层的权值参数;f’为f的导函数;$ \circ $ 表示对每个元素作乘法操作;up表示上采样操作。(2)对灵敏度求偏导
式中:k为卷积核参数;b为偏置项;u,v表示求偏导过程;
${(p_i^{l - 1})_{u,v}}$ 为计算$x_j^l$ 的过程中与$k_{ij}^l$ 对应相乘后的$x_i^{l - 1}$ 。(3)更新卷积层参数k和b
式中:
$\eta $ 为学习率。由反向传播过程知,调优过程中参数的更新速度和方向均与f的导函数f’有关,因此导函数f’是否计算方便将直接影响信息在网络中的流动速度,结合前向传播可知,激活函数在网络中每一层都会被频繁使用,所以激活函数的导函数求解是否方便、计算是否简单同样对网络的效率有着极大的影响。结合公式(1)可知,改善ReLU、LeakyReLU等函数缺陷的方式主要是通过优化激活函数的负半轴实现,而在函数负半轴引入非零函数的同时,还要注意避免因函数本身运算复杂度而导致的计算效率低和训练困难问题。
-
ReLU[3]函数由于其负半轴函数为零而存在神经元“坏死”缺陷;LeakyReLU[4]等函数以及组合函数虽然以不同的方式在弥补了ReLU的缺陷,但由于函数内部引入了额外的可训练参数或指数型复杂运算而造成了网络效率低、训练难的问题,因此从激活函数负半轴数学模型出发,设计了包括线性型、幂数型、分数型及自然对数型函数在内的四种函数进行实验,以寻找最佳的激活函数设计方案。
算法复杂度[11]由算法的时间复杂度和算法的空间复杂度两部分决定,其中时间复杂度与函数阶次相关,影响计算效率;空间复杂度与函数中包含的参数数量相关,决定了占用硬件资源情况。常见的函数复杂度从低到高依次为常数阶<线性阶<对数阶、分数阶、幂数阶<平方阶<指数阶<含超参函数,其中简单的线性函数、幂函数、分数函数及自然对数函数相较于引入了指数运算及额外参数的激活函数在计算上更加方便,这对于加快网络训练效率具有一定的优势。为了方便描述,上述四种激活函数分别用f1、f2、f3、f4表示,对应的导函数分别用f1’、f2’、f3’、f4’表示,其中四种激活函数表达式见表 1。
Function Function model f1 ${f_1}(x) = \left\{ {\begin{array}{*{20}{c}} {\;\;x\;,x \geqslant 0} \\ { - x,x < 0} \end{array}} \right.$ f2 ${f_2}(x) = \left\{ {\begin{array}{*{20}{c} } {\quad \;\;x\;\;\;\;\;\,\;,x \geqslant 0} \\ { - \dfrac{2}{3}{ {( - x)}^{\frac{3}{2} } },x < 0} \end{array} } \right.$ f3 ${f_3}(x) = \left\{ {\begin{array}{*{20}{c} } {\quad x\;\;,x \geqslant 0} \\ {\dfrac{x}{ {1 - x} },x < 0} \end{array} } \right.$ f4 ${f_4}(x) = \left\{ {\begin{array}{*{20}{c}} {\;\;\;{\kern 1pt} {\kern 1pt} {\kern 1pt} x\quad ,x \geqslant 0} \\ { - {{\ln }^{1 - x}},x < 0} \end{array}} \right.$ Table 1. Mathematical models of four activation functions
表中,f1函数的设计思路是根据ReLU正半轴的线性函数反向延长至整个定义域上的完整线性函数,在继承ReLU函数优点的基础上解决了其原来存在的神经元“坏死”缺陷;f2函数的设计思路是通过将原ReLU函数的零负半轴用简单的幂函数代替后构成的,这里幂参数及系数的设置是为了保证其导函数系数为最简形式;f3函数则是通过将原ReLU函数的零负半轴用简单的分数函数代替后构成的,分式形式是为了保证其导函数系数为最简形式且在整个定义域上连续;f4函数是通过将原ReLU函数的零负半轴用自然对数函数代替后构成的,自然对数函数时间复杂度和空间复杂度相对较低,在计算和求导方面均具有一定的优势,其系数设置同样是为了保证其导函数系数最简且在整个定义域上连续。激活函数f1、f2、f3、f4对应的图像如图 1所示。

Figure 1. (a) f1, (b) f2, (c) f3, (d) f4 functions and images
f1、f2、f3、f4均解决了ReLU函数在负半轴上图像为零的问题,有效改善了信息在网络前向和反向传播过程中的完整性,进而提高模型拟合能力,在一定程度上有效提升模型精度。f1为线性函数,f2为幂函数,f3为一阶分数函数,f4为自然对数函数,时间复杂度上,f1 < f2, f3, f4,相较于包含指数运算(如ELU)的激活函数更低,这决定了上述激活函数在计算方面更高效;在空间复杂度方面,上述函数相较于添加了额外参数(如LeakyReLU)的函数在空也更低,这决定了上述激活函数在占用硬件空间资源方面更少。
函数求导是否方便同样影响模型计算效率,常见函数类型有线性函数、幂函数、分数函数、对数函数、指数函数等,其中线性型函数求导过程为:
幂型函数求导过程为:
分数型函数求导过程为:
自然对数型函数求导过程为:
指数型函数求导过程为:
这里,k、α、e表示函数参数。由分析可知,线性函数求导时主要是对系数k的计算,超参数个数为1;幂函数求导时同时对参数k和α进行计算,参数个数为2;分数型函数求导时除了计算参数α,还要对分式函数二次求导,参数个数为1;对数函数求导时仅计算参数α,参数个数为1;指数函数求导时不仅要计算系数k、α和e,同时需要二次求导,超参个数为2,而含有额外超参的激活函数中超参个数更多,由此可见,线性函数、幂函数和自然对数函数在求导方面效率较高,分数函数次之,指数函数效率相对最低。对f1、f2、f3、f4依次求导得到相应的导函数f1’、f2’、f3’、f4’,四种导函数模型如表 2所示。
Derived function Function model f1’ ${f_1}^\prime (x) = \left\{ {\begin{array}{*{20}{c}} {\;\,1\;,x \geqslant 0} \\ { - 1,x < 0} \end{array}} \right.$ f2’ ${f_2}^\prime (x) = \left\{ {\begin{array}{*{20}{c}} {\;\quad \;\;1\quad \;,x \geqslant 0} \\ { - \sqrt {( - x)} ,x < 0} \end{array}} \right.$ f3’ ${f_3}^\prime (x) = \left\{ {\begin{array}{*{20}{c} } 1 \\ {\dfrac{1}{ { { {(1 - x)}^2} } } } \end{array} } \right.\begin{array}{*{20}{c} } {,x \geqslant 0} \\ {,x < 0} \end{array}$ f4’ ${f_4}^\prime (x) = \left\{ {\begin{array}{*{20}{c} } {\;\;\;1\;\;{\kern 1pt} \;,x \geqslant 0} \\ {\dfrac{1}{ {1 - x} },x < 0} \end{array} } \right.$ Table 2. Four kinds of activation function derivative function model
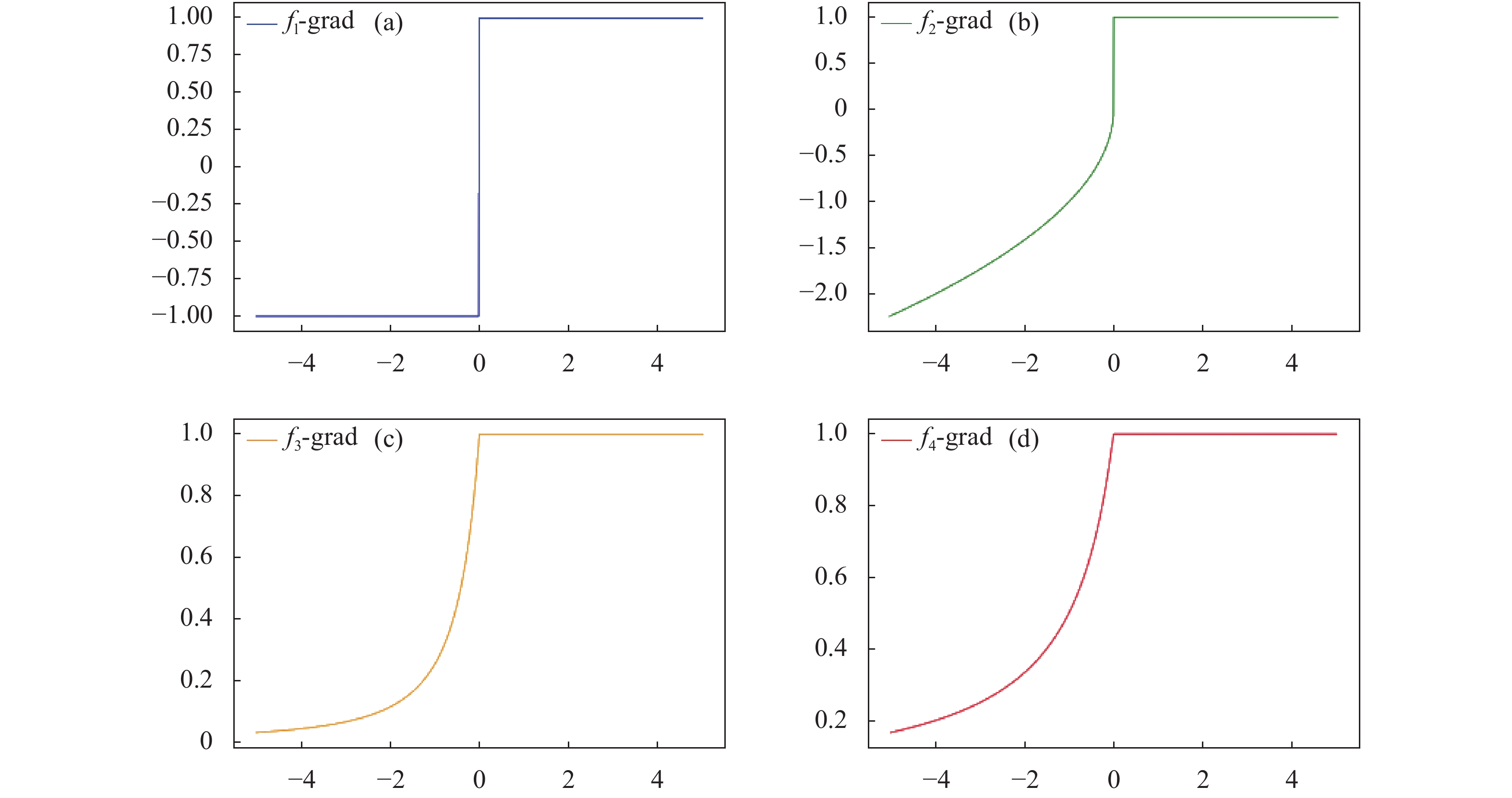
可见,f1’、f2’、f3’、f4’解决了ReLU导函数在负半轴上图像为零的问题,促进了信息在网络中传递,进而达到改善模型精度的目的。f1’为常函数,f2’为幂函数,f3’为二阶分数函数,f4’为一阶分数函数,时间复杂度上,f1’ < f2’, f4’ < f3’且均低于包含指数运算(如ELU)的激活函数;空间复杂度上,f1’ < f2’, f3’, f4’且均低于引入了额外超参数(如LeakyReLU)的激活函数,综上可知,上述导函数相较于ReLU及其改进型函数的导函数算法复杂度更低,计算效率更快,相应地占用硬件资源也更少。四种导函数图像如图2所示。

Figure 2. Derivatives of (a) f 1, (b) f 2 ,(c) f 3 ,(d) f 4 and their graphs
结合CNN模型前向和反向传播过程,由于上述四种激活函数及其导函数相较于已有激活函数(如ELU、LeakyReLU)在时间和空间复杂度上更低,因此f1、f2、f3、f4四种函数理论上在促进网络中信息传递和加速训练方面相较于其它基于ReLU的改进函数效果更好,接下来通过相应实验来验证各激活函数的具体性能。
-
实验在CIFAR10[12]、CIFAR100[12]及Fer2013[13]数据集上开展。数据集CIFAR10和CIFAR100均是32×32的彩色图像,分别包含10、100个类别,Fer2013为细粒度分类数据集,由35886张48×48人脸表情图片组成,共7类。实验均在Pytorch1.5.0、Python3.8、NVIDIA GTX 2080显卡环境下进行,完整迭代轮数均为120个Epoch,实验中学习率设置为0.001,优化器采用随机梯度下降+动量法(SGD+Moument)。使用准确率ACC(%)和训练时长T/h作为评价指标用以评估不同激活函数的综合性能。
-
为了确定最佳的EReLU函数设计方案,按照上述方法使用VGG16[12]和ResNet18[14]网络分别采用f1、f2、f3、f4及ReLU函数在CIFAR10和CIFAR100数据集上测试,Batchesize设置为128,测试结果如表3、表4所示。
Results
MethodsDatasets CIFAR10 CIFAR100 ACC T/h ACC T/h f1 93.11% 1.332 74.82% 1.332 f2 93.03% 1.335 74.27% 1.335 f3 93.66% 1.290 75.23% 1.290 f4 93.78% 1.262 75.87% 1.262 ReLU 92.90% 1.325 73.68% 1.325 Table 3. Performance of different activation functions on the ResNet18 network
Results
MethodsDatasets CIFAR10 CIFAR100 ACC T/h ACC T/h f1 91.31% 1.225 58.91% 1.225 f2 91.24% 1.248 58.35% 1.248 f3 91.86% 1.243 59.23% 1.243 f4 91.98% 1.175 59.95% 1.175 ReLU 91.15% 1.238 56.24% 1.238 Table 4. Performance of different activation functions on the VGG16 network
实验结果表明,f4在不同网络和数据集上综合表现均最好,f2、f3略差,f1最差,但都优于ReLU函数,这与函数及其导函数本身的时间复杂度及空间复杂度有一定的关系,其中f1为线性函数,f2为幂函数,f3为一阶分数函数,f4为自然对数函数,时间复杂度上,f1 < f2, f3, f4,相较于包含指数运算(如ELU)的激活函数更低,这决定了上述激活函数在计算方面更高效;在空间复杂度方面,上述函数相较于添加了额外参数(如LeakyReLU)的函数在空间复杂度上更低,这决定了上述激活函数在占用硬件空间资源方面更少。由此可见,在负半轴引入上述任意非零函数均对ReLU函数的性能有所改善,其中引入了自然对数函数的f4综合表现最佳,因此采用f4作为高效激活函数EReLU的最终设计方案,即
-
确定了EReLU函数的数学模型后,为了更有效的说明其优越性,使用VGG16[12]和ResNet18[14]并分别采用EReLU、ReLU[3]、LerkyReLU[4]、PReLU[5]、ELU[6]、ReLU-softsign[8]共6种激活函数在CIFAR10[12]、CIFAR100[12]数据集上按照上述方式进一步实验。
(1) CIFAR10上实验结果及分析
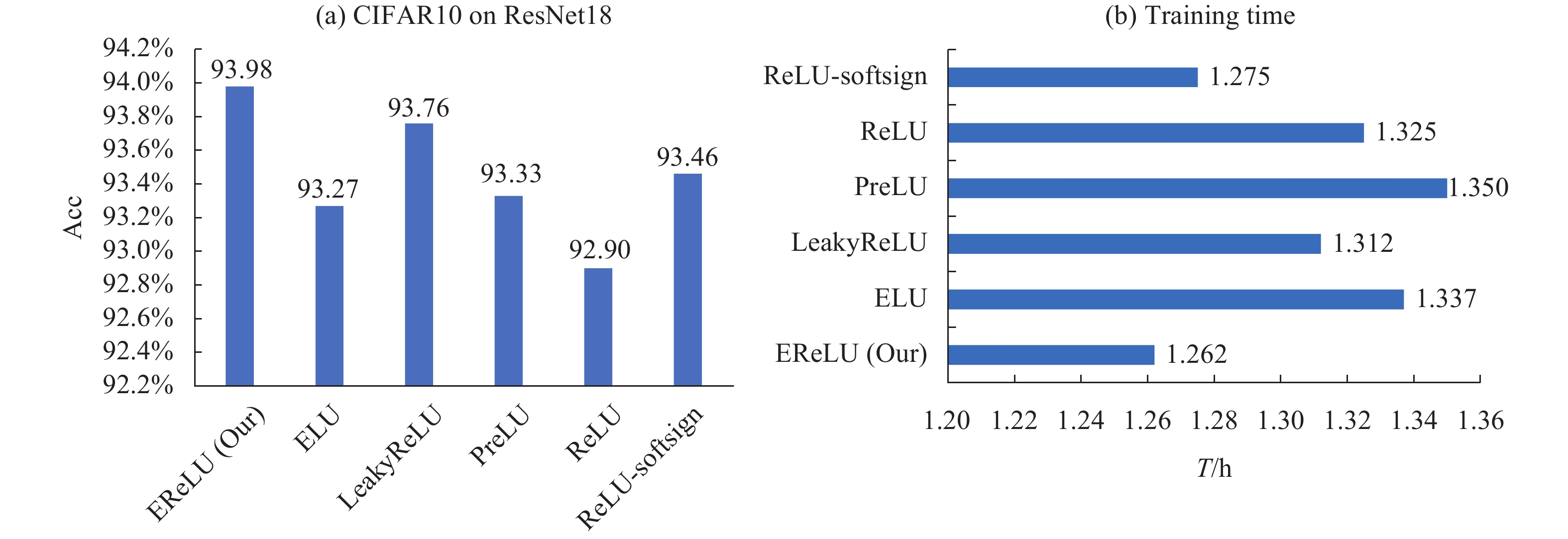
使用ResNet18和VGG16网络在CIFAR10数据集上的测试结果分别见图3、图4,其中图图3(a)纵坐标表示分类准确率,横坐标表示不同的激活函数,图3(b)纵坐标表示不同的激活函数,横坐标表示训练时长,其中黑色粗体表示最好的结果,蓝色表示第二好结果,后续图中的坐标轴含义均与图3相同。

Figure 3. Test accuracy (a) and training time (b) of different activation functions using ResNet18 network on CIFAR10

Figure 4. Test accuracy (a) and training time (b) of different activation functions using VGG16 network on CIFAR10
由图3、图4可见,在标签少、类间距大的CIFAR10上使用两种网络对上述6种函数测试时,EReLU表现最佳,ReLU-softsign第二,PReLU表现最差,EReLU在提升精度和效率方面均表现最佳,相较于其他函数在CIFAR10上精度提升幅度为0.85%~1.08%,时长缩短范围为0.075~0.088 h。
(2) CIFAR100上实验结果及分析
由图5、图6可见,在标签多、类间距小的CIFAR100数据集上使用两种网络对上述6种函数测试时,ERelu函数在精度和效率方面综合表现最佳,PReLU次之,ReLU最差,EReLU相较于其他函数在CIFAR100上精度提升幅度为2.19%~3.71%,时长缩短范围为0.075~0.088 h。

Figure 5. Test accuracy (a) and training time (b) of different activation functions using ResNet18 network on CIFAR100

Figure 6. Test accuracy (a) and training time (b) of different activation functions using VGG16 network on CIFAR100
(3) Fer2013上实验结果及分析
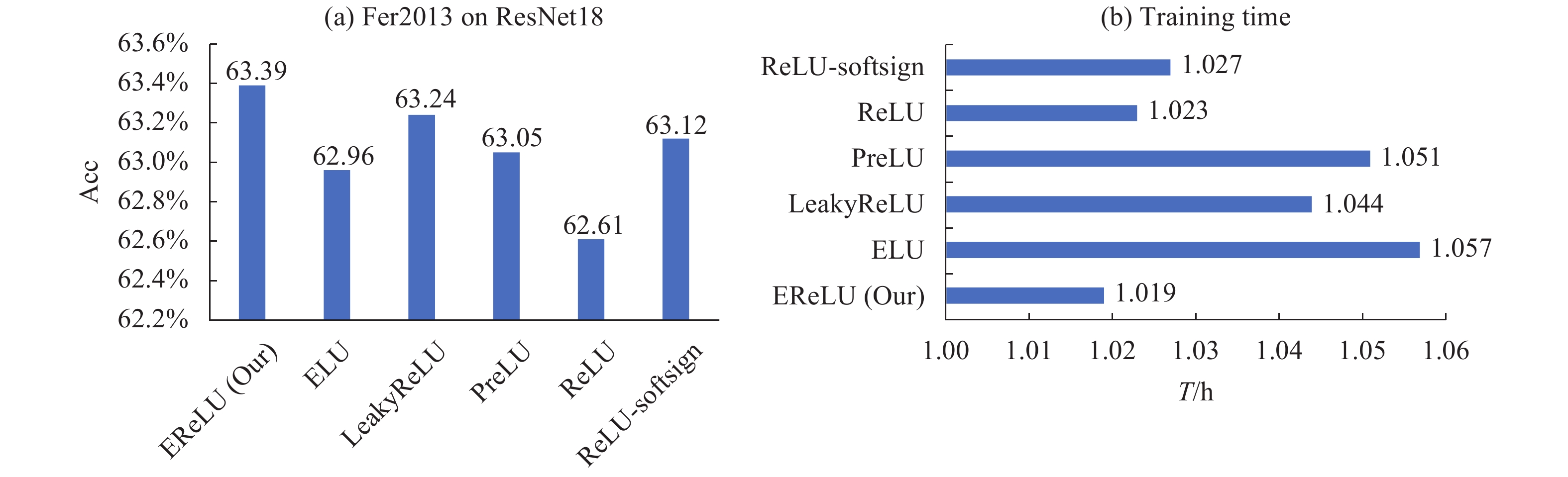
由图7、图8可见,在标签少、类间距小的细粒度数据集Fer2013上使用两种网络对上述6种函数测试时,EReLU在提升精度和效率方面同样表现最佳,ReLU-softsign次之,PReLU则最差,EReLU相较于其他函数在Fer2013上精度提升幅度为0.58%~0.78%,时长缩短范围为0.015~0.038 h。

Figure 7. Test accuracy (a) and training time (b) of different activation functions using ResNet18 network on Fer2013

Figure 8. Test accuracy (a) and training time (b) of different activation functions using VGG16 network on Fer2013
综合图3~图8可知,EReLU和ReLU-softsign函数在标签少、类间差异小的细粒度数据集上潜力较大,LeakyReLU和PReLU函数在标签多、类间差异大的数据集上表现较好,而ELU仅在标签少、类间差异大的数据集上精度略优于ReLU,但效率上有所下降,而反观EReLU函数,相较于其他函数在提升精度和效率方面表现均最好。由此可见,EReLU在图像分类任务中相比于其他激活函数更具优越性和竞争力。
-
文中通过分析激活函数在网络训练过程中的作用提出包括线性型、幂数型、分式型及自然对数型在内的4种改进ReLU激活函数的方案,实验表明当在负半轴引入自然对数函数时可以更好的提升网络性能,由此确定EReLU函数的数学模型。随后在ResNet18和VGG16网络中使用EReLU、ReLU、LerkyReLU、PReLU、ELU及ReLU-softsign共6种激活函数分别在CIFAR10、CIFAR100和Fer2013数据集上进行测试,结果表明EReLU相较于其他函数精度提升0.12%~6.61%,效率提升1.02%~6.52%,由此可见,EReLU函数在提升轻量型网络的精度和效率方面相较于其它激活函数更具竞争力。
在未来的工作中,将EReLU函数应用到大型神经网络或其他领域的数据集进行测试,以进一步验证EReLU函数的优越性和适用性。
High efficient activation function design for CNN model image classification task
doi: 10.3788/IRLA20210253
- Received Date: 2021-12-10
- Rev Recd Date: 2022-01-25
- Publish Date: 2022-04-07
Fund Project:
Natural Science Foundation of Anhui Province(2108085ME158);National Natural Science Foundation of China 面上项目(52174141);Anhui University Collaborative Innovation Project(GXXT-2020-54);Key Research and Development Program of Anhui Province(202004a07020043)
-
Key words:
- image classification /
- high efficiency activation function /
- neurons ''necrosis'' /
- convolutional neural network
Abstract: Activation Functions (AF) play a very important role in learning and fitting complex function models of convolutional neural networks. In order to enable neural networks to complete various learning tasks better and faster, a new efficient activation function EReLU was designed in this paper. By introducing the natural logarithm function, EReLU effectively alleviated the problems of neuronal "necrosis" and gradient dispersion. Through the analysis of the activation function and its derivative function in the feedforward and feedback process of the mathematical model of the EReLU function exploration and design, the specific design of the EReLU function was determined through test, and finally the effect of improving the accuracy and accelerating training was achieved; Subsequently, EReLU was tested on different networks and data sets, and the results show that compared with ReLU and its improved function, the accuracy of EReLU is improved by 0.12%-6.61%, and the training efficiency is improved by 1.02%-6.52%, which strongly proved the superiority of EReLU function in accelerating training and improving accuracy.




















 DownLoad:
DownLoad: