







HTML
-
人脸检测作为面部信息处理的基础技术,被广泛的应用到人脸识别[1]、人脸跟踪[2]、人脸特征点定位[3]和人脸属性分析[4]等任务,其检测结果直接影响后续步骤的精确性和稳健性,具有重要的研究意义。人脸检测可分为约束场景下的人脸检测和非约束场景下的人脸检测[5],后者包含跨光谱[6]、多人密集环境[7]、局部遮挡[8]等多种复杂环境。由于约束场景下的人脸检测较为简单,而非约束场景下的人脸检测受人脸尺度多样性、姿态多样性、遮挡、模糊等条件影响比较困难,因此当前人脸检测的研究热点主要集中于非约束场景。
作为人脸检测的先驱,参考文献[9]提出了一种基于Haar-like特征和AdaBoost级联分类器的人脸检测方法,取得了相对较好的检测效果,但其仍局限于人工设计特征的弱描述能力。
在神经网络迅速发展的今天,研究人员已经开始使用更强特征描述能力的卷积神经网络(Convolutional
$ {\rm{Neural}} $ $ {\rm{Networks}} $ , CNN)[10-11]来取代传统方法进行人脸检测,并且在检测精度、速度和适应性等方面取得了较大的提高。比如Cascade CNN[12],就是AdaBoost人脸检测方法的卷积神经网络实现,和传统方法相比,Cascade CNN具有更高的检测精度和速度。虽然基于CNN的人脸检测方法进一步提高了人脸检测的准确率,但对非约束场景下的小尺寸人脸检测仍具难度。基于卷积神经网络的人脸检测方法主要分为两种:第一种是两阶段人脸检测方法,先在区域建议网络[13](
$ {\rm{Region}} $ $ {\rm{Proposal}} $ Network, RPN)中经过端到端的训练,再将训练得到的区域候选图送入到Faster RCNN进行分类和回归;另一种是源于单一神经网络物体检测器(Single Shot MultiBox Detector, SSD)的人脸检测方法[14],它不需要进行候选区域的建议,直接在多尺度卷积层上执行$ 人脸/背景 $ 分类和人脸边界框位置回归。参考文献[15]提出了一种融合面部区域上下文信息的人脸检测方法,对小尺寸人脸检测效果较好,但运算时效性低。参考文献[16]通过等比例补偿锚匹配策略提升对小尺寸人脸的正样本分辨能力,通过max-out标签增强了人脸分类能力和检测准确度。参考文献[17]提出了一种基于背景协作描述的单一神经网络人脸检测方法,通过扩大检测框的感受野提高了对小尺寸人脸的检测精度。文中基于SSD人脸检测模型,针对非约束场景下的小尺寸人脸检测,从以下3个方面进行了改进:(1)提出了一种特征增强网络。在SSD基础检测网络的两个浅层特征图上,通过协调聚合当前层特征图和前后两层特征图的特征信息,增强了当前层特征图的鉴别性和稳健性,提高了对小尺寸人脸的检测精度。(2)对两个检测小尺寸人脸的增强特征图,进行负样本筛选,通过增加分类的难度来降低由小尺寸锚框引起的人脸检测假正率升高。(3)为增强特征图和原始特征图分别建立两种基于锚框尺寸的损失函数,并进行加权融合。
-
与先生成RPN再进行目标检测的算法不同,SSD算法可直接预测目标类别和检测框位置,具有较高的检测精度和很快的检测速度。该算法通过在不同尺度特征图上进行
$ {\rm{3}} \times {\rm{3}} $ 尺寸的滑动卷积,可实现精度较高的尺度不变人脸检测结果。基于SSD基础检测网络的人脸检测模型如图1所示。
Figure 1. Face detection model based on SSD basic detection network
由图1可知,
$ {\rm{Conv1\_1}}-{\rm{Conv5\_3}} $ 是$ {\rm{VGG16}} $ 的前5个卷积层,$ {\rm{Conv6}} $ 和$ {\rm{Conv7}} $ 是由$ {\rm{VGG16}} $ 的2个全连接层FC6和FC7改造的卷积层,$ {\rm{Conv8\_2}}-{\rm{Conv11\_2}} $ 是新增的4个卷积层。该模型的输入是包含一个或多个面部的图像,输出是一系列人脸检测框及其对应的面部得分,当所有人脸检测框执行非最大值抑制后,得到最终的人脸检测结果。该SSD人脸检测模型的损失函数包含了人脸/背景分类的softmax损失
$ {L_{conf}} $ 和人脸检测框回归的smooth L1损失$ {L_{loc}} $ :式中:
$ N $ 为匹配到人脸检测框的数量;$ x $ 为检测框属于人脸的得分,是则取1,不是则取0;$ c $ 为检测目标的人脸置信度;$ {t_i} $ 为人脸预测框;$ t_i^ * $ 为人脸真实框;$ \lambda $ 为平衡softmax损失和smooth L1损失的权重。在训练时,为了提高运行效率和检测效果,对正负训练样本比例进行控制。首先计算先验框和真实框的交并比
$ (\rm{Intersection\;over \;Union, IoU}) $ ,取$ {\rm{IoU}} > 0.5 $ 的先验框为正样本,其余先验框为负样本。接着,将检测框与负样本集进行一一匹配,删除匹配失败的检测框以平衡正负样本数量,提高训练的收敛速度。 -
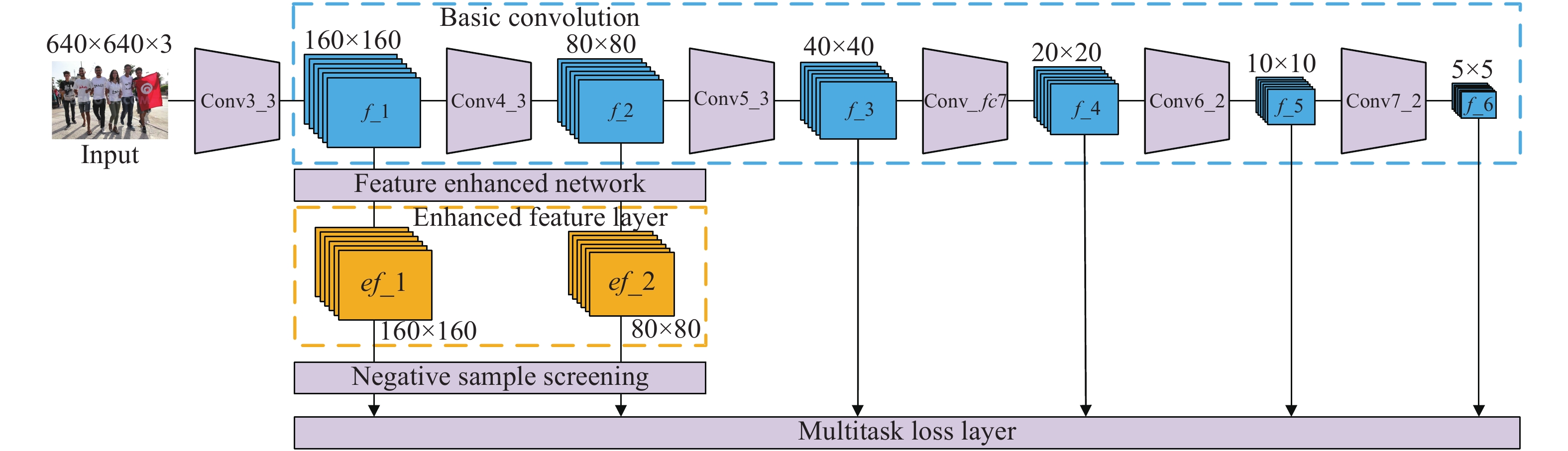
文中提出的基于增强卷积神经网络的尺度不变人脸检测模型如图2所示,该模型主要分为基础卷积层、特征增强网络、增强特征层和多任务损失层4个部分。
基础卷积层采用SSD模型从Conv3_3~Conv7_2的6个多尺度卷积层,每层对应生成的特征图为f_1(160×160)、f_2(80×80)、f_3(40×40)、f_4(20×20)、f_5(10×10)和f_6(5×5)。其中,前2个特征图f_1和f_2被送入特征增强网络进行特征增强。后4个特征图直接被用来进行人脸/背景分类和人脸边界框位置回归。

Figure 2. Scale-invariant face detection model based on enhanced convolutional neural network
特征增强网络负责协调组合当前层特征图和前后两层特征图的上下文信息。对这3层特征图进行归一化卷积、上采样、下采样、点乘、连接和扩张卷积等操作后,得到当前层特征图的增强特征图,并且它们的尺寸与当前层特征图保持一致。由于浅层特征图更适合进行小尺寸目标检测,因此增强特征图ef_1和ef_2被用来进行小尺寸人脸检测。另外,在训练时还为ef_1和ef_2加入了负样本筛选,通过增加分类的难度来降低由小尺寸锚框引起的人脸检测假正率升高,进一步提高了人脸检测精度。
-
参考文献[13]指出,浅层特征图更适合被用来检测小尺寸人脸,因此,文中提出了特征增强网络来增强浅层特征图f_1和f_2的鉴别性和稳健性,以进一步提高对小尺寸人脸的检测精度。在增强第k层特征图时,需要协调组合第k−1层、第k层和第k+1层特征图的上下文信息,其网络结构如图3所示。

Figure 3. Feature enhancement network
由图3可以看出,第k−1层、第k层和第k+1层特征图的尺寸和维度均不相同,此时不能直接进行特征图的增强融合。因此,可先遍历采用1×1尺寸卷积核对上述特征图进行尺寸和维度的归一化处理,使3层特征图的维度相同。然后分别对第k−1层特征图进行下采样,对第k+1层特征图进行上采样,使3层特征图的尺寸也都为2l×2l。接着,对第k−1层特征图和第k层特征图进行逐元素点乘,对第k层特征图和第k+1层特征图进行逐元素点乘,并将点乘后的2个新特征图连接,得到2l×2l大小的融合特征图。最后,对融合特征图进行扩张卷积(扩张率分别是2、3、4),得到特征图f_k的增强特征图ef_k。以上步骤可归纳如下:
式中:
$ {f_{{\rm{conv1}}}} $ 表示遍历采用1×1尺寸卷积核执行归一化卷积;$ {f_{{\rm{down}}}} $ 表示对第k-1层特征图进行下采样;$ {f_{{\rm{up}}}} $ 表示对第k+1层特征图进行上采样;$ {f_{{\rm{Dot}}}} $ 表示对两个特征图进行逐元素点乘;$ {f_{{\rm{connect}}}} $ 表示对两个新特征图${{nf}}\_{{k}}{\rm{ - 1}}$ 和${{nf}}\_{{k}} + 1$ 进行连接;$ {f_{{\rm{2,3,4 - dilated\_conv3}}}} $ 表示扩张率分别是2、3、4,卷积核大小为3×3的扩张卷积。 -
基于锚框的人脸检测方法可以被视为一个二元分类问题,即确定锚框所包围的区域是人脸还是背景。由于人脸在整张图像上所占的面积较小,这会导致正负训练样本的严重不匹配,只有一小部分锚框对应的是人脸,而绝大多数锚框对应的是背景,这会增加人脸检测的假正率。这种严重的正负训练样本不匹配主要是由小尺寸人脸检测引起,为了检测小尺寸人脸,必须在图像上密集平铺数量庞大的小尺寸锚框,这会导致负训练样本的急剧增加。为了解决这个问题,文中对ef_1和ef_2这两个检测小尺寸人脸的增强特征图,进行了负样本筛选,通过增加分类的难度来降低由小尺寸锚框引起的人脸检测假正率升高,该过程的示意图如图4所示。

Figure 4. Schematic diagram of negative sample screening
由图4可知,对于ef_1和ef_2这两个增强特征图,输出通道数设置为(Nc+1)+4,其中Nc+1对应Nc个负样本概率和1个正样本概率,4对应人脸边界框回归的位置坐标[x, y, Δx, Δy]。对于每个匹配到真实人脸框的锚框,同时预测Nc个该锚框的背景锚框,然后选择其中得分最高的背景锚框作为负样本与正样本一起完成softmax二分类:
式中:
$ b' $ 表示得分最高背景锚框的概率;$ {b_1} $ ~$ {b_{{N_{\rm{c}}}}} $ 表示Nc个预测背景锚框的概率。通过这种局部优化方法,可以降低负训练样本比例,同时增强对小尺寸人脸的检测能力。对于从f_3~f_6这四个特征层,输出通道数设置为2+4,其中2表示人脸/背景的二元分类概率,4表示人脸边界框回归的位置坐标。 -
在浅层特征图上更适合进行小尺寸人脸检测,因此,文中算法在训练时为ef_1和ef_2这两层增强特征图,设置了基于小尺寸锚框
$ {\hat r_i} $ 的损失函数,为f_3、f_4、f_5和f_6这四层特征图设置了基于正常尺寸锚框$ {r_i} $ 的损失函数,并通过加权求和来融合上述两种损失函数。ef_1和ef_2这两层增强特征图对应的损失函数为:
式中:
$ {N_{conf}} $ 表示正负样本锚框数量;$ {L_{conf}} $ 表示对人脸和背景的分类损失;$ {p_i} $ 表示预测为人脸的概率;$ p_i^ * $ 表示正负样本标签;$ {N_{loc}} $ 表示正样本锚框的数量;$ {L_{loc}} $ 表示使用锚框$ {\hat r_i} $ 时人脸预测框$ {t_i} $ 和真实框$ t_i^ * $ 之间的参数化$ {\rm{smooth }}{L_1} $ 损失,当$ p_i^ * = 1 $ 时,激活$ {L_{loc}} $ ,并通过权重$ \alpha $ 来平衡$ {L_{conf}} $ 和$ {L_{loc}} $ 。f_3、f_4、f_5和f_6这四层特征图对应的损失函数为:
式中:锚框
$ {r_i} $ 的尺寸是$ {\hat r_i} $ 的两倍。将ef_1和ef_2的损失函数与f_3、f_4、f_5和f_6的损失函数加权融合,得到均衡化处理后的新损失函数$ {L_{Sum}} $ :式中:
$\; \beta $ 表示均衡$ {L_{ef}}({p_i},{t_i},{\hat r_i}) $ 和$ {L_f}({p_i},{t_i},{r_i}) $ 的权重。 -
为了验证所提出算法的精确性和稳健性,选择FDDB[18]和WIDER FACE[19]人脸检测基准数据集进行实验,选择HR[15]、SFD[16]和PyramidBox[17]算法作为比较算法。实验中所有算法都在PyCharm上基于python代码实现,并且代码运行环境为配置Nvidia GTX Titan X的计算机。在训练时,对所有的卷积层参数都使用Xavier方法[20]随机初始化,模型优化方法采用随机梯度下降,批大小设置为32,权重衰减设置为0.0005,动量设置为0.9,最大迭代次数设置为
$ 12 \times {10^4} $ ,前$ 8 \times {10^4} $ 次迭代,学习率设置为$ {10^{ - 3}} $ ,后$ {\rm{4}} \times {10^4} $ 次迭代,学习率设置为$ {10^{ - 4}} $ 。文中算法使用WIDER FACE的训练集进行训练,并在两个数据集上进行测试。 -
首先,在FDDB数据集上测试在WIDER FACE数据集上训练好的模型。FDDB数据集共有2845个图像,其中标记了5171张具有模糊,遮挡,低分辨率和姿势变化的人脸。在测试之前,需要将FDDB数据集的人脸椭圆标注转化为矩形框。
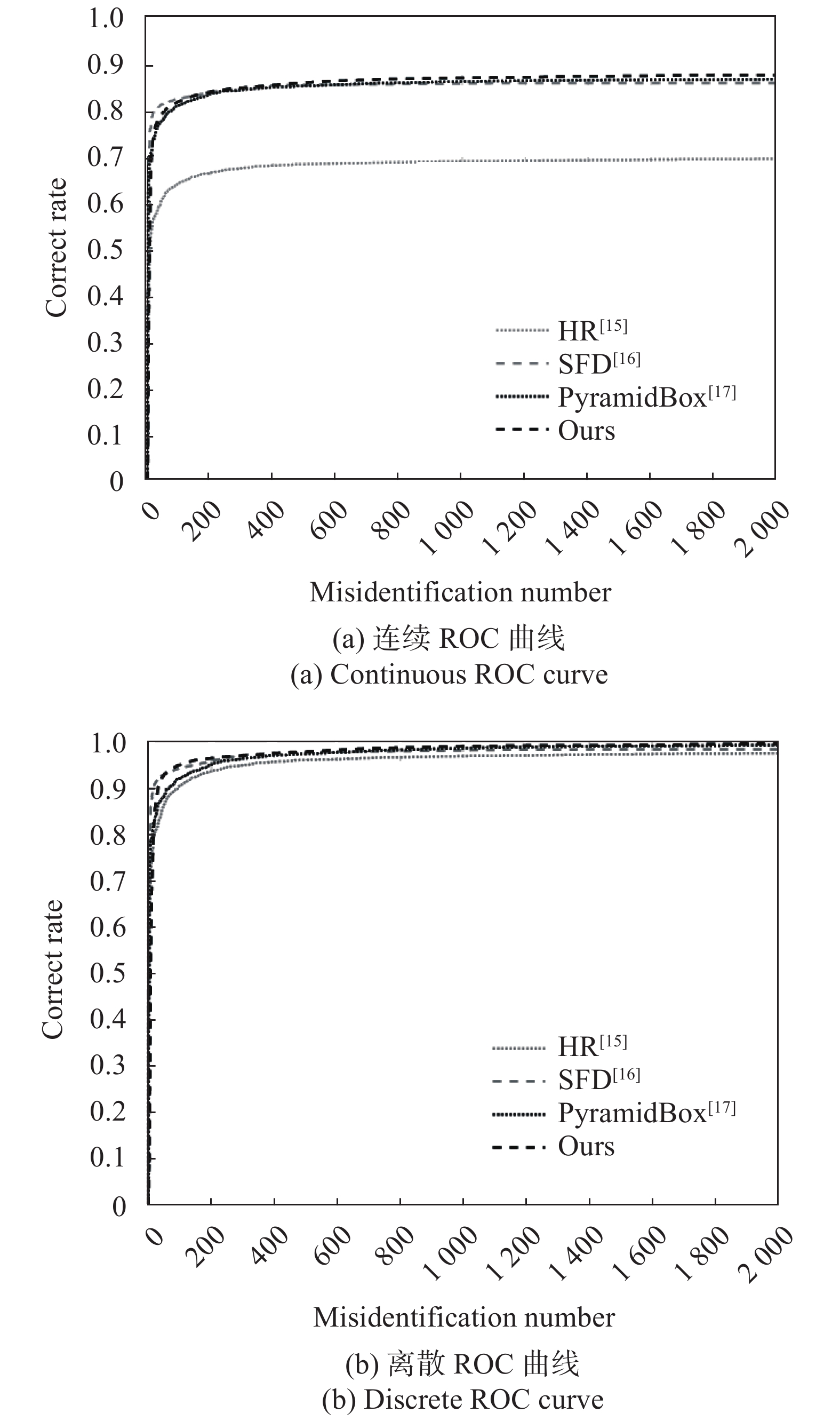
文中算法与HR,SFD和PyramidBox算法在FDDB数据集上的连续ROC曲线和离散ROC曲线如图5所示。由图5可知,连续ROC曲线在离散ROC曲线之下,因为连续ROC曲线关注于IoU越大越好,而离散ROC曲线仅关注IoU是否大于0.5。FDDB数据集上的检测精度可通过不同误识别数下的正确率来描述,在低误识别数时,文中算法的正确率略低于SFD算法,在高误识别数时,文中算法的正确率均高于其他3种主流人脸检测算法。这说明文中算法通过引入特征图增强、负样本筛选和基于锚框尺寸的损失函数,进一步提高了人脸检测的精确性。

Figure 5. ROC curves of HR, SFD, PyramidBox and proposed algorithm on FDDB dataset
-
WIDER FACE数据集共有32203个图像,其中标记了393703张具有模糊、多尺度、多姿态、局部遮挡和不同光照等多种要素的人脸。该数据集共包含61种情景,每种情景分别随机选择40%、10%、50%的数据作为训练,验证和测试子集。其中,验证子集和测试子集根据检测难度,被划分为3种难度级别,分别是简单、适中和困难。WIDER FACE数据集上的检测精度为真正人脸占全部检测人脸的比例。文中选择WIDER FACE的测试子集进行实验,实验结果如图6所示。

Figure 6. Precision-Recall curves of HR, SFD, PyramidBox and proposed algorithm on WIDER FACE test subset
观察图6可以发现,对于简单、适中和困难这三个难度级别的测试,文中算法的精度和召回率曲线(Precision-Recall, PR)都在其他3种主流人脸检测算法之上。根据PR曲线的定义,如果一种检测算法的PR曲线高于另外一种检测算法,则前者具有更强的检测性能,这说明文中算法具有比其他3种对比算法更强的检测性能。文中算法在WIDER FACE测试子集上的部分检测结果如图7所示。由图7可知,文中算法实现了较好的小尺寸人脸检测效果。

Figure 7. Partial detection results of proposed algorithm on WIDER FACE test subset
-
文中提出了一种基于增强卷积神经网络的尺度不变人脸检测方法。该方法在SSD基础检测网络的两个浅层特征图上,通过协调聚合当前层特征图和前后两层特征图增强了当前层特征图的辨识度。接着对经过增强的两个特征图进行负样本筛选,降低了由小尺寸锚框引起的人脸检测假正率升高。最后,为原始特征图和增强特征图设置了两种基于锚框尺寸的损失函数以增强对小尺寸人脸的检测效果。在FDDB和WIDER FACE数据集上的测试结果表明,文中算法的检测精度高于当前主流的人脸检测方法。下一步将注重于增强网络模型对人脸可见区域的特征响应,以提升文中方法对遮挡人脸的检测效果。


































































 DownLoad:
DownLoad: