







-
在图像拍摄过程中,由于相机抖动、拍摄对象快速移动或失焦等原因导致的图像质量大幅衰减的现象称为图像退化,将退化图像恢复为清晰图像的技术称为图像恢复技术,图像去模糊技术属于图像复原技术的一种。模糊图像会严重影响后续计算机视觉任务的性能,通常在目标检测[1-2]、图像分割[3]和目标跟踪[4]等高级计算机视觉任务中大多数都假设输入图像是无模糊的,一旦输入的图像是模糊的,这些任务往往无法准确检测或分割图像中的模糊对象。由于图像去模糊技术能显著提高输入模糊图像的后续计算机视觉任务的性能,图像去模糊技术受到了国内外学者的广泛关注[5-6]。传统的去模糊方法[7-12]通常对模糊核做出假设,对不同类型的均匀、非均匀以及深度感知模糊进行建模并施加各种约束条件,利用图像的先验信息求解模糊核,最后从给定的模糊图像中恢复出对应的清晰图像。尽管传统的方法易于实现,但这些方法大多对模糊模型的假设比较简单,不能很好地去除真实世界中复杂的非均匀模糊。此外,传统的去模糊方法计算推理复杂且大多需要多次迭代来优化参数,使得图片处理时间过长,从而限制了算法的实际应用。随着深入学习研究的深入,许多基于深度学习的去模糊算法[13-17]不断地被提出,此类方法不依赖于自然图像的先验知识,能够以端到端的方式学习模糊图像和对应的清晰图像之间的非线性映射关系,从而能更好地处理动态场景中的非均匀模糊。早期的深度学习方法[14]主要使用单一尺度的网络架构,但由于单尺度网络感受野较小,在编码上下文信息方面效率较低难以提取更全面的全局特征和局部特征。为此Nah等人[5]提出一种基于多尺度的去模糊网络,该网络由多个子网络组成,每个子网络输入一张缩小的图像,并以“从粗到细”的方式逐渐恢复清晰的图像。由于多尺度的方法被证明是有效的,许多基于多尺度的去模糊方法逐渐被提出[16-17],然而这些多尺度方法都是将多个子网络堆叠到一起,使得网络训练更加复杂并且运行时间更长。因此文中提出一种结合多尺度特征融合和多输入多输出编-解码器的去模糊算法,不同于Nah等人[5]的多个子网输入不同尺度图像的方法,文中的多尺度特征能够输入到单一的编码器中,同时解码器能输出多张不同尺度的清晰图像,网络更加简单并且能有效去除图像模糊。具体来说,文中贡献如下:
(1)提出一种结合多尺度特征融合和多输入多输出编-解码器的去模糊算法。相比其他堆叠多个子网的多尺度模糊方法,网络复杂度较低。
(2)为了有效利用多尺度特征信息,分别提出了多尺度特征提取模块(Multi-scale feature extraction module,MFEM)和多尺度特征渐进融合模块。此外,文中基于SAM[18]设计了一个特征注意力模块(Feature attention module,FAM)来增强或抑制不同尺度的特征信息,从而提高网络学习并区分特征的能力。
(3)文中利用峰值信噪比(Peak signal to noise ratio,PSNR)和结构相似性(Structural similarity,SSIM)对所提出的网络进行量化评估。大量的实验结果表明,在合成数据集GoPro和HIDE中,文中方法相较其他基准方法具有更高的PSNR和SSIM。在真实数据集RealBlur-R和RealBlur-J上的结果表明,文中方法具有更好的泛化性和鲁棒性。
(4)为了进一步评估文中算法在后续高级计算机视觉任务上的应用价值,使用预先训练的YOLOv4[1]对模糊图像和去模糊后的图像进行目标检测。结果表明文中算法能够有效提升后续高级计算机视觉任务的性能。
-
Yuan等人[6]使用模糊图像以及对应的同一场景下包含噪声的清晰图像来估计模糊核,通过利用噪声图像中清晰的细节信息来较好地估计初始核,并提出了残差反卷积来减少图像反卷积固有的振铃伪影。但由于对模糊核的估计过于单一且假设模糊核是空间不变的,使得该方法不能很好地处理真实相机抖动造成的非均匀模糊。为此,Whyte等人[8]提出了一个参数化几何模型,该模型能有效处理由于相机旋转引起相机抖动产生的非均匀图像模糊。但该方法忽略了相机平移造成的图像模糊,仅对相机旋转建立了几何模型。针对相机平移造成的运动模糊,Xu等人[9]提出了一种基于L0稀疏表示的运动去模糊方法。该方法在优化过程中不需要额外的滤波,仅需要少量的迭代就能够收敛。Hu等人[11]考虑到模糊图像中的光线条纹包含丰富的模糊信息,提出了一种利用光线条纹进行建模的弱光图像去模糊方法,该方法通过检测模糊图像中有用的光条纹来估计模糊核从而去除模糊。Pan等人[12]观察到模糊图像的暗通道具有更小的稀疏性,提出一种基于暗通道先验的图像盲去模糊方法,该方法不需要任何复杂的模糊核估计就能够去除非均匀模糊。
近年来,由于深度神经网络具有强大的特征学习以及非线性建模能力,其在目标检测,目标分割,图像恢复等计算机视觉任务中得到广泛应用。Sun等人[13]首先将卷积神经网络(CNN)应用到图像去模糊领域,该方法通过预测小图像块上运动模糊的概率分布来估计非均匀运动模糊核,并利用小图像块的先验来去除运动模糊。然而,使用具有均匀运动模糊的小图像块训练CNN忽略了较大区域上模糊图像和运动模糊核的映射关系,因此该方法去模糊性能不佳。之后,Gong等人[15]将整张图片的运动模糊表示为像素方向的线性运动模糊,再通过CNN直接估计模糊图像中的运动流来恢复出清晰图像。总的来说,早期基于CNN的去模糊方法大多通过利用CNN来估计模糊核从而复原图像,然而当模糊核估计不准确时,这些方法很难实现理想的去模糊效果。因此,最近的去模糊方法大多以端到端的方式直接训练无核估计的网络来复原图像。Nah等人[5]提出了一个基于高斯金字塔结构的多尺度卷积神经网络,这种由粗到细的网络结构能够充分提取图像的多尺度特征来恢复清晰图像。但使用独立的子网络分别训练每个尺度的图像,使得网络总体参数量较大且训练困难。为此,Tao等人[19]在不同的多尺度特征提取子网络中共享参数,在提升网络去模糊效果的同时,减少了网络参数并降低了运行时间。但该方法忽略了图像特征的尺度变化特性,所有子网共享参数的方式可能会丢失多尺度特征信息,使得网络不能有效的复原图像细节信息。Gao等人在参考文献[20]的基础上提出了一种有效的参数选择性共享网络,并在网络的非线性变换模块中引入了一种新的嵌套跳跃连接结构来代替简单地堆叠卷积块来提高网络性能。Kupyn等人[21-22]将生成对抗网络(GAN)应用于图像去模糊,先后提出了DeblurGAN、DeblurGAN-v2使用生成对抗网络将模糊图像直接映射到清晰图像来去除模糊,然而这两种方法很难复原复杂场景下的非均匀动态模糊。Zhang等人[23]提出了一个端到端的多层次去模糊网络,该网络的每个子网能够提取由不同分割方式产生的小图像块的细节特征,并逐层融合提取到的特征信息来复原图像。Cai等人[24]将暗通道和亮通道先验信息嵌入神经网络中来聚合通道特征,并对网络进行稀疏正则化操作来提高网络性能。但先验知识的加入提高了模型建模的复杂度,在真实模糊场景下模型的泛化性能不佳。为此,Zhang等人[25]考虑到目前去模糊数据集大多为合成数据集,使用生成对抗网络生成真实的模糊图像,从而提高网络模型在真实场景下的去模糊性能。Park等人[26]提出了一种基于多时相递归神经网络的单幅图像去模糊算法,该算法首先将深度模糊分解成一系列轻度模糊,然后再以迭代的方式逐步去除模糊。Zou等人[27]提出一种基于小波变换的扩张网络去模糊算法,该算法使用具有不同扩张率的扩张卷积来获得具有不同感受野的特征,并利用小波变换模块来恢复图像的纹理细节信息。
-
文中所提出的整体网络架构如图1所示,该网络包含四个子模块,分别为编码网络块 (Encode Block, EB)、解码网络块 (Decode Block, DB)、多尺度特征提取模块 (Multi-scale Feature Extraction Module, MFEM)和多尺度特征渐进融合模块 (Progressive Multi-scale Feature Fusion Module, PMFM)。其中第一个编码网络块EB1由一个卷积层和一个残差组(Residual Group, RG)构成,残差组由多个残差块(Residual Block, RB)堆叠而成,每个残差块包含两个3×3卷积。第二个编码网络块EB2和第三个编码网络块EB3在EB1的基础上增加了特征注意力模块来自适应地学习不同尺度的有用特征并减少冗余特征。与第一个编码网络块EB1对应的是第一个解码网络块DB1,该网络块由一个卷积层和一个RG组成,第二个解码网络块DB2和第三个解码网络块DB3在DB1的基础上增加了转置卷积,利用转置卷积来进行上采样操作从而恢复特征图大小。
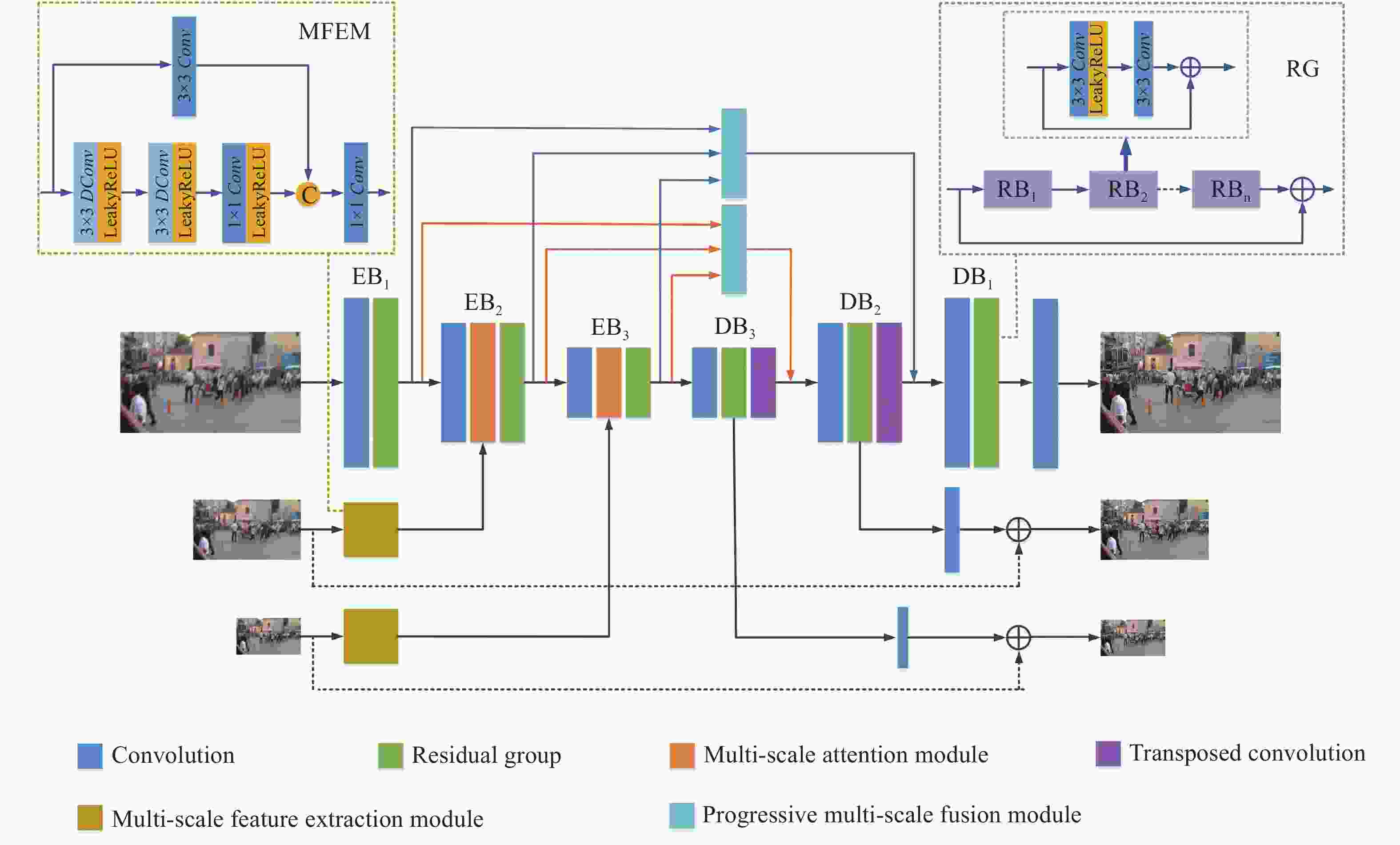
Figure 1. Network architecture of algorithm
在编码阶段,首先将输入模糊图像B1、B2和B3的分辨率大小缩放为256×256、128×128和64×64。把分辨率大小为256×256的模糊图像B1作为第一个编码网络块EB1的输入,利用多尺度特征提取模块来提取分辨率大小为128×128的模糊图像B2和分辨率大小为64×64的模糊图像B3中的多尺度特征,然后再将提取到的特征分别输入到第二个编码网络块EB2和第三个编码网络块EB3中的特征注意力模块中来增强或抑制不同尺度的特征信息,使得更多有用的特征输入到下一模块。在每个编-解码网络块间使用多尺度特征渐进融合模块逐步融合EB1、EB2和EB3提取到的多尺度特征,将其输入到解码网络块中在不同尺度清晰图像的监督下逐步复原图像。
在解码阶段,将多尺度特征渐进融合模块提取到的特征信息分别与第二个解码网络块DB2和第三个解码网络块DB3的输出特征进行融合,使得网络能够充分学习不同特征间的互补信息,减少图像细节信息的丢失。在每个解码网络块中,使用与输入模糊图像分辨率大小相同的清晰图像对不同尺度的输出图像进行监督。解码阶段中图像恢复过程可表示为:
式中:
$ {\rm{MFFM}}_n^{\rm{out}} $ 为第n个多尺度特征融合模块的输出;${\rm{DB}}_{n + 1}^{\rm{out}} $ 和$ {\rm{EB}}_n^{\rm{out}} $ 分别表示第n+1个解码网络块和第n个编码网络块的输出;$ {\rm{DB}}_n $ 表示在第n个解码网络块上进行解码操作;$ Conv $ 为卷积操作,将特征图通道数恢复至3通道来得到清晰图像。 -
为了提取不同分辨率大小的模糊图像B2和B3中的初始特征,文中设计了一个多尺度特征提取模块。如图2所示,该模块通过两条支路并行提取特征信息。其中一条支路中首先使用两个扩张卷积来捕捉模糊图像中每个像素点的全局特征和局部特征。扩张卷积通过在标准卷积的卷积核中插入空洞,以此来扩大感受野,相比普通卷积能够以较少的参数量获得更大的感受野。其次再将提取到的特征输入一个普通1×1卷积进行特征细化,其中卷积层后的激活函数均为LeakyReLU激活函数。此外由于扩张卷积的卷积结果之间没有相关性,这会导致部分局部信息的丢失,为了减少传输过程中细节信息的丢失,MFEM在另一条支路中使用一个3×3卷积来提取更精细的特征,在不增加过多计算量的情况下同时获得全局和局部的特征信息。

Figure 2. Multi-scale feature extraction module
最后将两条支路的特征图进行拼接,并使用一个1×1卷积融合特征信息并调整通道数。该模块可以描述为:
式中:Bn为不同分辨率大小的模糊图像且n的取值为2或3;F1为Bn通过第一条支路后输出的特征图;F2为Bn通过第二条支路后输出的特征图;
$ {\rm{MFFM}}_n^{\rm{out} }$ 为多尺度特征提取模块的输出;Convn表示卷积核大小n×n的普通卷积;DConv3表示扩张卷积,卷积核大小为3×3且扩张率为3;δ表示LeakyReLU激活函数。 -
为了能够自适应地学习不同尺度特征中的有用信息,受SAM[18]启发,文中设计了一个特征注意力模块。与SAM不同,文中设计的FAM不需要使用清晰图像进行监督来生成注意力图,降低了网络的复杂度。FAM利用EB和MFEM的输出生成注意力图,为不同的特征图在空间上和通道上赋予不同的权重,从而增强或抑制不同尺度的特征信息,以此来提高网络学习并区分特征的能力。该模块能有效的减少冗余特征,使得更多有用的特征传播到下一模块中。
如图3所示,FAM有两个输入
${\rm{EB}}_n^{{\rm{out}} \downarrow } $ 和$ {\rm{MFFM}}_n^{\rm{out} }$ ,其中当n=1时,${\rm{EB}}_1^{{\rm{out}} \downarrow } $ 为第一个编码网络块输出特征通过一个步长为2的卷积下采样操作后得到的特征图,该特征图大小为128×128,$ {\rm{MFFM}}_1^{\rm{out}} $ 为MFEM提取到的特征图大小为128×128的多尺度特征。当n=2时,${\rm{EB}}_2^{{\rm{out}} \downarrow } $ 为第一个编码网络块输出特征通过一个步长为2的卷积下采样操作后得到的特征图,该特征图大小为64×64,$ {\rm{MFFM}}_2^{\rm{out}}$ 为MFEM提取到的特征图大小为64×64的多尺度特征。Fx是${\rm{EB}}_n^{{\rm{out}} \downarrow } $ 和$ {\rm{MFFM}}_n^{\rm{out}} $ 进行逐元素相加后得到的特征图,将其通过1×1卷积后并输入到Sigmoid激活函数中得到特征注意力图,利用特征注意力图中0~1之间的元素数值大小来表示不同信息在空间上和通道上的权重值,元素数值越大说明其对应位置特征信息获得了更高的关注,使得网络能够自适应地对特征图Fx中的关键信息进行学习。
Figure 3. Feature attention module
将特征注意力图与
$ {\rm{EB}}_n^{{\rm{out}} \downarrow } $ 经过1×1卷积后得到的特征进行逐元素相乘并输出特征Fy,以此来重新校准$ {\rm{EB}}_n^{{\rm{out}} \downarrow } $ 中的特征信息。最后,将Fy、经过卷积操作后的多尺度特征$ {\rm{MFFM}}_n^{\rm{out}} $ 和$ {\rm{EB}}_n^{{\rm{out}} \downarrow } $ 进行逐元素相加得特征注意力模块的输出FAMout,该模块可描述为:式中:
$ \oplus $ 表示特征图逐元素相加;$ \otimes $ 表示特征图逐元素相乘;Sig表示Sigmoid激活函数。 -
在传统的编-解码网络中,通常利用跳跃连接简单地将编码网络块中的单一尺度特征信息传递到对应的解码网络块中,使得解码网络块不能充分利用特征图的不同尺度特征信息,且网络间信息流不够灵活。为此,文中提出一个多尺度特征渐进融合模块(Progressive Multi-scale Feature Fusion Module, PMFM),对第一个编码网络块的输出
${\rm{EB}}_1^{{\rm{out}} \downarrow } $ 、第二个编码网络块的输出${\rm{EB}}_2^{{\rm{out}} \downarrow } $ 和第三个编码网络块的输出${\rm{EB}}_3^{{\rm{out}} \downarrow } $ 逐步进行融合。该模块能够让信息流在不同尺度之间进行交互,在从小尺度图像中捕获更多的上下文信息的同时,又能从大尺度图像中学习更多的细节特征。使得小尺度特征图信息能够被充分利用并对大尺度特征图信息进行互补,从而有效的融合不同尺度信息。与特征图简单拼接或逐元素相加的特征融合方式不同,文中提出的PMFM能够将小尺度特征图逐渐的融合到大尺度特征图中从而能够有效利用不同尺度的特征信息。如图4所示,该模块有3个输入即${\rm{EB}}_1^{{\rm{out}} \downarrow } $ 、${\rm{EB}}_2^{{\rm{out}} \downarrow } $ 和${\rm{EB}}_3^{{\rm{out}} \downarrow } $ ,其特征图大小分别为256×256、128×128、64×64。
Figure 4. Progressive multi-scale feature fusion module
在该模块中,将
${\rm{EB}}_1^{{\rm{out}} \downarrow } $ 通过一个1×1的卷积进行特征细化,并将细化后得到的特征与${\rm{EB}}_2^{{\rm{out}} \downarrow } $ 经过双线性上采样后得到的特征图进行拼接操作得融合后的特征图F1,然后将F1通过1×1卷积后与${\rm{EB}}_3^{{\rm{out}} \downarrow } $ 经过双线性上采样后得到的特征图进行拼接得融合后的特征图F2。并且为了减少在特征融合时较大尺寸特征图中高频细节信息的丢失,将第一个编码网络块提取到的高分辨率特征信息${\rm{EB}}_1^{{\rm{out}} \downarrow } $ 与特征图F2进行逐元素相加得到特征图F3。最后,使用1×1卷积对特征图F3进行信息整合并输出PMFMout,具体流程如下:式中:Conv为卷积操作,卷积核大小均为1×1;Concat表示对特征图在通道上进行拼接;up为双线性上采样操作;PMFMout为多尺度特征融合模块的输出。
-
在图像恢复任务中,训练网络常用的损失函数是均方误差(Mean Square Error, MSE)损失函数。MSE对网络输出图像和真实图像在对应像素点上计算差值并进行平方,但由于平方操作通常会惩罚较大的误差值并容忍较小的误差值,会导致输出结果过度平滑且图像边缘模糊。因此,文中在训练网络时采用L1损失和SSIM损失组成的混合损失,总体损失函数L可以表示为:
式中:M为训练集每个batch输入网络的图片数目;n表示第n个尺度,当n为1时,表示对第一个尺度中分辨率大小为256×256的图像求损失;当n为2时,表示对第二个尺度中分辨率大小为128×128的图像求损失;当n=3时,表示对第三个尺度中分辨率大小为64×64的图像求损失;X为文中网络输出的图像;Y为对应的清晰图像;λ为权重因子。
(1) L1损失
L1损失不会过度惩罚较大的误差值,能够保留图像结构和边缘信息,L1损失数学表达式为:
(2) SSIM损失
由于SSIM损失[28]是基于局部对比度、亮度和结构等局部图像特征来进行计算,所以使用SSIM损失来训练网络能获得更好的图像视觉效果,且能够较好地保留图像细节等高频信息,SSIM损失可以表示为:
式中:
${u_X}$ 及${u_Y}$ 、${\sigma _X}$ 及${\sigma _Y}$ 和${\sigma _{XY}}$ 分别为文中网络输出的图像和对应的清晰图像的平均值、方差和协方差;C1和C2均为常数使得整体公式稳定,文中取C1=0.01,C2=0.03。 -
文中使用GoPro数据集来训练网络模型,该数据集由Nah等人[5]利用GoPro运动相机拍摄每秒240帧的视频序列,并对连续的多帧短曝光图像取平均来生成模糊图像。共包含3214对分辨率为1280×720的清晰图像和模糊图像,其中文中使用2103对图像进行训练,1111对图像进行测试。为了评估网络的泛化能力,文中还使用HIDE数据集和RealBlur数据集对网络模型进行测试。HIDE数据集由Shen等人[29]提出,该数据集主要包含多种场景下的人物运动模糊,共由8422对模糊图像和清晰图像组成,其中测试集由2025对的模糊图像和清晰图像组成。与GoPro和HIDE数据集不同,RealBlur数据集[30]的图像对是在真实环境中采集的,包含232个不同场景的4738对图像,该数据集由共享相同图像内容的两个子集组成,其中一个子集RealBlur-R由相机原始图像组成,另一个子集RealBlur-J由经过相机处理后的JPEG图像组成。其中训练集包含3758对图像,测试集包含980对图像。
-
文中方法基于PyTorch框架实现,采用NVIDIA GeForce RTX 3060 12 G GPU对模型进行训练和测试。采用动量衰减指数β1=0.9,β2=0.999的Adam优化器更新网络参数,迭代次数为1000次。初始学习率设置为10−4,每迭代200次学习率减半。在每一轮训练迭代过程中,随机选取6张裁剪为256 pixel×256 pixel大小的图像作为网络输入,并通过随机旋转和垂直翻转的方式来增强数据。文中使用GoPro数据集对网络进行训练,并将训练好的模型在GoPro数据集、HIDE数据集和真实数据集RealBlur上测试。
-
文中算法与经典去模糊算法以及目前基于深度学习的主流算法进行比较,如表1所示,经典算法有:Whyte等人[8]、Xu等人[9]和Pan等人[12]提出的算法,目前基于深度学习的去模糊算法有:DeblurGAN-v1[21],DeblurGAN-v2[22],SRN[19],MT-RNN[26],DBGAN[25],DMPHN[23]以及Nah等人[5]和Gao等人[20]提出的算法。由于以上基于深度学习的去模糊算法均使用GoPro数据集对网络进行训练,所以文中直接使用作者公开发布的源代码对GoPro数据集、HIDE数据集和RealBlur数据集进行测试,并采用峰值信噪比[31](Peak Signal-to-Noise Ratio, PSNR)、结构相似性[28](Structural Similarity, SSIM)作为评价指标对所恢复的图像质量进行定量评价。由表1数据可知,文中算法在四个数据集上均取得了最佳效果,在GoPro数据集上PSNR为31.73 dB,SSIM为0.951,较DMPHN[23]分别提升了0.34 dB和0.004,在HIDE数据集上PSNR为29.39 dB,SSIM为0.923,与MT-RNN[26]相比PSNR和SSIM分别提升了0.24 dB和0.006。在真实数据集RealBlur-J和RealBlur-R上,文中算法与其他基于深度学习的去模糊算法差异较小,但仍达到了最佳效果,与第二名DeblurGAN-v2[22]相比PSNR和SSIM分别提升了0.02 dB和0.001。由四个数据集上的测试结果可知,相比其他方法,文中算法去模糊效果较好,并具有更好的泛化能力和鲁棒性。
Method GoPro HIDE RealBlur-R RealBlur-J PSNR SSIM PSNR SSIM PSNR SSIM PSNR SSIM Xu et al.[9] 22.85 0.817 21.78 0.723 31.63 0.872 24.88 0.822 Whyte et al.[8] 24.47 0.843 22.81 0.735 30.56 0.854 25.92 0.844 Pan et al.[12] 24.73 0.876 23.92 0.763 32.92 0.891 25.79 0.854 DeblurGAN-v1[21] 25.64 0.859 23.96 0.809 34.28 0.932 27.01 0.865 Nah et al.[5] 27.83 0.915 25.73 0.874 33.92 0.947 27.11 0.876 DeblurGAN-v2[22] 29.08 0.918 27.51 0.884 34.16 0.942 27.17 0.877 SRN[19] 30.24 0.934 28.36 0.903 34.24 0.937 27.08 0.876 Gao et al.[20] 30.96 0.942 29.1 0.913 34.06 0.943 26.82 0.868 MT-RNN[26] 31.12 0.944 29.15 0.917 34.19 0.95 26.74 0.869 DBGAN[25] 31.18 0.946 28.94 0.915 32.99 0.926 24.87 0.821 DMPHN[23] 31.39 0.947 29.1 0.916 34.12 0.948 26.63 0.865 Ours 31.73 0.951 29.39 0.923 34.35 0.951 27.19 0.878 Table 1. Test results on various datasets
-
除了通过评价指标PSNR和SSIM对文中算法进行定量分析,文中还从GoPro数据集、HIDE数据集、RealBlur-J和RealBlur-R数据集随机选取不同场景的图像与目前主流算法进行视觉效果对比分析。图5、6、7分别展示了不同算法在GoPro数据集上、HIDE数据集和RealBlur数据集的去模糊图像视觉效果。从图5中可以看出,Xu等人[9]和Pan等人[12]提出的传统算法难以处理非均匀模糊,使得重建后的图像中仍存在大量模糊。通过对比图5中第一张图片中的汽车后视镜可以得出,文中算法对后视镜的边缘轮廓重建效果最好,DeblurGAN-v2[22]去除模糊不彻底,不能很好的恢复出主体轮廓,而DBGAN[25]能恢复出后视镜轮廓,但存在伪影无法重建图像细节。通过对比图5中第四张图片中的车牌数字可以看出,在所有对比方法中只有文中算法能清晰的恢复出数字,SRN[19]和MT-RNN[26]等算法重建的图像边缘不够清晰,无法看出清晰的数字。

Figure 5. Comparison of the visual results of each model on the GoPro dataset

Figure 6. Comparison of the visual results of each model on the HIDE dataset

Figure 7. Comparison of the visual results of each model on the RealBlur dataset
通过对比图6中第二张图片的字母区域可以看出,文中算法对字母区域的恢复最为清晰,Nah等人[5]提出的算法能去除部分模糊,但不能清晰的恢复出每个字母,SRN[19]相比Nah等人[5]提出的算法去模糊效果明显提高,但仍不能有效恢复出字母的边缘等高频信息。对比图7中的第一张图片的数字区域可以看出,文中算法能很好地恢复出数字轮廓,取得了较好的主观效果。
通过3.3.1节对表1中各方法进行定量对比分析,以及3.3.2节对图5、图6和图7的主观视觉效果对比分析的结果可知,文中方法能够很好地处理非均匀模糊,对图像边缘轮廓和细节等信息重建效果更好,去模糊更为彻底。同时相比目前主流的去模糊方法,文中方法在基准数据集GoPro、HIDE和真实数据集RealBlur-R、RealBlur-J上均取得了最佳效果,具有更好的泛化能力和鲁棒性。
-
为了验证提取多尺度特征对网络去模糊性能提升的有效性,文中在GoPro数据集上训练并测试了编-解码网络不同多输入多输出个数N(尺度数)的PSNR和SSIM。当N=1时,编-解码网络只输入输出一张分辨率大小为256×256的单一尺度图像;当N=2时,编-解码网络输入输出两张分辨率大小分别为256×256和128×128的图像;当N=3时,编-解码网络输入输出三张分辨率大小分别为256×256、128×128和64×64的图像。当N=4时,编-解码网络输入输出四张分辨率大小分别为256×256、128×128、64×64和32×32的图像。测试结果如表2所示,从表2中可以看出,当使用单输入单输出编解码器时,PSNR和SSIM值分别为31.22和0.944。当N=3时,PSNR和SSIM分别提升了0.51和0.007,证明了多尺度特征提取的有效性。当N=4时,PSNR和SSIM相比N=3仅分别提升了0.09和0.001,这是因为输入图像的尺度过小只包含很少的信息,这些特征信息对网络的去模糊性能提升较小。此外,现有的多尺度去模糊方法[5, 20, 24]都是三尺度结构网络。因此,文中选择N=3作为最终网络模型的尺度数。
N PSNR SSIM 1 31.22 0.944 2 31.58 0.949 3 31.73 0.951 4 31.85 0.952 Table 2. Ablation study on different number of input and output numbers of encoder-decoder
-
文中算法设计的编-解码网络块中的残差组由多个残差块堆叠而成,为了评估残差块的个数对网络性能的影响,在GoPro数据集上对残差块的个数M做了消融实验,M的取值分别为4,8,12,16,18,20,24。实验结果如表3所示,当M=4时,PSNR和SSIM值较低,分别为27.97和0.933。随着残差块数量的增多,PSNR和SSIM值也随之提升,当M=20时,PSNR和SSIM值分别为31.73和0.951。由图8可知,当M大于20时,PSNR和SSIM的增加速率减缓,为了平衡参数量和去模糊性能,文中取M值为20。
-
文中算法在GoPro数据集进行了多种模块不同组合的消融实验。首先,评估了不同的特征融合方法对网络性能的影响,将文中所提出的多尺度特征融合模块MPFM与普通特征图通道拼接(Concatenate)和逐元素相加(Sum)的融合方法进行比较。如表4所示,使用逐级特征融合模块与使用逐元素相加的融合方法相比,PSNR提高了0.16,SSIM提高了0.006。与使用特征图拼接的融合方法相比,PSNR提高了0.08,SSIM提高了0.003。其次,为了验证提取多尺度特征提取模块MFEM对网络去模糊性能的影响,用一个3×3卷积来代替文中的多特征提取模块。从表4中可以看出,使用MFEM时PSNR提高了0.09,SSIM提高了0.003。最后,为了验证特征注意力模块FAM的有效性,对FAM进行消融实验,由表4可知,去掉FAM模块后,PSNR下降了0.03,SSIM下降了0.001。图9为FAM所生成注意力图的可视化结果,从图中可以看出,相较于背景,人物运动造成的模糊区域获得了更高的权重,这说明FAM能够强调不同的局部特征并关注模糊程度较高的区域。
M 4 8 12 16 20 24 28 PSNR 29.97 30.63 31.21 31.42 31.73 31.75 31.76 SSIM 0.933 0.939 0.944 0.948 0.951 0.951 0.951 Table 3. Ablation study on different number of residual blocks

Figure 8. Analysis of the number of residual blocks
-
图像去模糊是一项基本的低级计算机视觉任务,其最终目标是服务于后续高级计算机视觉任务。由于相机抖动、物体快速运动以及低快门速度等因素造成的图像非均匀模糊,在很大程度上会降低高级计算机视觉任务的性能。然而现有的目标检测算法往往假设输入图像是无模糊的,使得这些算法无法精确的检测到模糊图像中的对象。为了评估文中算法在目标检测算法中的有效性,使用YOLOv4[1]对模糊图像和去模糊后的图像进行目标检测。如图10所示,未经文中算法处理的模糊图像识别率较低或无法识别出对象,而去模糊后的图像识别率显著提高,能够识别出更多对象。因此,文中算法能够通过有效去除模糊来增强目标检测算法的鲁棒性。

Figure 10. Comparison of visual results of target detection
Module Combination of different modules MPFM √ Sum Concatenate √ √ MFEM √ √ √ × √ FAM √ √ √ √ × PSNR 31.73 31.57 31.65 31.64 31.7 SSIM 0.951 0.945 0.948 0.948 0.95 Table 4. Ablation study with different module combi-nations

Figure 9. Attention map visualization for FAM
-
针对现有的大多数去模糊算法仍存在去模糊不彻底且图像细节信息丢失等问题,文中提出一种结合多尺度特征融合和多输入多输出编-解码器的去模糊算法。首先通过一个基于扩张卷积多尺度特征提取模块来提取较小尺度图像的特征,然后通过特征注意力模块来为不同尺度的特征图在空间上和通道上赋予不同的权重,从而提高网络学习并区分特征的能力。提出了一个多尺度特征渐进融合模块不同尺度的特征逐步融合在一起,能够减少了网络传输过程中高频细节信息的丢失。此外,为了降低网络训练的复杂度,区别于堆叠多个编-解码子网来输入和输出多尺度图像的方式,文中网络模型使用单一编-解码结构,将多尺度图像输入输出到同一个编-解码器中,以“从粗到细”的方式逐步恢复清晰图像。实验结果表明,文中算法在基准数据集GoPro和HIDE以及真实数据集RealBlur上相较于目前先进的去模糊算法均取得了较好的客观评价和主观视觉效果,并且能够提升后续计算机视觉任务的性能。
Image deblurring via multi-scale feature fusion and multi-input multi-output encoder-decoder
doi: 10.3788/IRLA20220018
- Received Date: 2022-01-06
- Rev Recd Date: 2022-03-04
- Available Online: 2022-11-02
- Publish Date: 2022-10-28
Fund Project:
National Natural Science Foundation of China(62066047, 61966037)
-
Key words:
- image deblurring /
- image restoration /
- deep learning /
- multi-input multi-output /
- multi-scale networks
Abstract: A deblurring method combining multi-scale feature fusion and a multi-input multi-output encoder-decoder is proposed for non-uniform blurred images caused by camera shake, fast motion of the captured object, and low shutter speed. Firstly, the initial features of smaller-scale blurred images are extracted using a multi-scale feature extraction module, which uses dilated convolution to obtain a larger receptive field with a smaller number of parameters. Second, the feature attention module is used to adaptively learn useful information from different scale features, which can effectively reduce redundant features by using features of small-scale images to generate attention maps. Finally, the multi-scale feature progressive fusion module is applied to gradually fuse features at different scales, making the information of different scale features to complement each other. Compared with recent multi-scale methods that use multiple subnets stacked on top of each other, we use a single network to extract multi-scale features, thus reducing the training difficulty. To evaluate the deblurring effect and generalization performance of the network, the proposed method is tested on both the benchmark datasets GoPro, HIDE, and the real dataset RealBlur. The peak signal-to-noise ratio values of 31.73 dB and 29.39 dB and the structural similarity values of 0.951 and 0.923 on the GoPro and HIDE datasets, respectively. The deblurring performance is higher than that of recent state-of-the-art deblurring methods, and it also has better performance on the RealBlur dataset containing real scenarios. The experimental results demonstrate that the proposed method is more effective than recent deblurring methods, can effectively restore the edge contour and texture detail information of images. In addition, our method can improve the robustness of subsequent high-level computer vision tasks.













































 DownLoad:
DownLoad: